
As data architects, we know healthcare data is more abundant than ever—spanning electronic health records (EHRs), claims, genomics, clinical trials, and patient-reported outcomes. But abundance doesn’t equal usability. Most of this data is noisy, disjointed, and incompatible. Without remastering, healthcare data remains underutilized, disconnected, and inconsistent due to fragmentation and inconsistency across these sources. That’s where data remastering comes in—and why it’s one of the most underrated enablers of AI and analytics in Healthcare and Life Sciences today.
Data remastering is the process of transforming, enriching, and standardizing diverse datasets into a unified format to create a more accurate, complete, and interoperable version…essentially making the data more usable.
It goes beyond basic data cleaning by focusing on deep normalization, entity resolution, standard alignment (like OMOP, SNOMED, and ICD-10), and enrichment with additional context or sources. It’s especially valuable in industries like Healthcare and Life Sciences, where fragmented, siloed, or outdated data limits analytics, AI applications, and regulatory compliance.
The goal of data remastering is to make data interoperable, complete, and trustworthy—so your downstream AI models and analytics don’t fall apart under the weight of messy input.
Data remastering helps by:
Data remastering is a critical enabler for AI and advanced analytics in both hospitals and life sciences companies because AI models and insights are only as good as the data they’re built on. Garbage in, garbage out.
Data remastering, especially of addresses, provider data, patient identities, and service locations, provides huge value to hospitals and health systems. It is foundational for everything from compliance to cost control to strategic growth. For example, hospitals and health systems benefit from remastered data to correctly link patient encounters across systems and times, ensure accurate patient journeys, validate addresses for population health and SDOH analysis, and enable more accurate referral leakage modeling by deduplicating providers and standardizing referral patterns.
Let’s say you’re trying to build a longitudinal patient journey. Without remastering:
After remastering:
Suddenly, your patient data is usable. And your analysts aren’t spending weeks manually reconciling records.
For Life Science companies, data remastering merges fragmented HCP information like NPI, specialty, affiliations for HCP/KOL targeting, links patient-level data across EHRs, claims and labs for RWE and HEOR studies, tracks longitudinal events across siloed datasets for patient journey analysis, and cleans site performance data for clinical trial site selection optimization.
Let’s say you’re targeting oncologists for a KOL engagement. If “Dr. A. Smith,” “Andrew Smith MD,” and “Smith, A.” all appear separately across trials, speaker data, and publications—you’ll miss out. Remastering merges those identities using NPI, affiliations, and specialty to create a high-confidence, unified provider profile.
Now you’re targeting the right physician with the right message at the right time
Many cloud-based platforms provide an optimized environment for healthcare data remastering, leveraging AI, machine learning, and scalable computing. Because of the massive volume of healthcare data from multi-source EHRs to claims and lab data, Data Intelligence Platforms can scale without performance bottlenecks, and unlike traditional siloed data warehouses, unified data lakehouse architecture enable near real-time ingestion, integration and processing of disparate healthcare datasets, making insights readily available. Kythera’s platform, Wayfinder, provides advanced data cleaning and standardization using automated data pipelines, AI/ML-driven data deduplication, missing value imputation, de-identification, and standardization, all on a secure, efficient platform.
Let’s take a look at how typical patient data may look before remastering. As you can see, there may be different patient IDs across systems, medical codes may be used inconsistently, variations in provider and facility names, and data that may not be linked. All these data inconsistencies create problems with usability and outcomes.
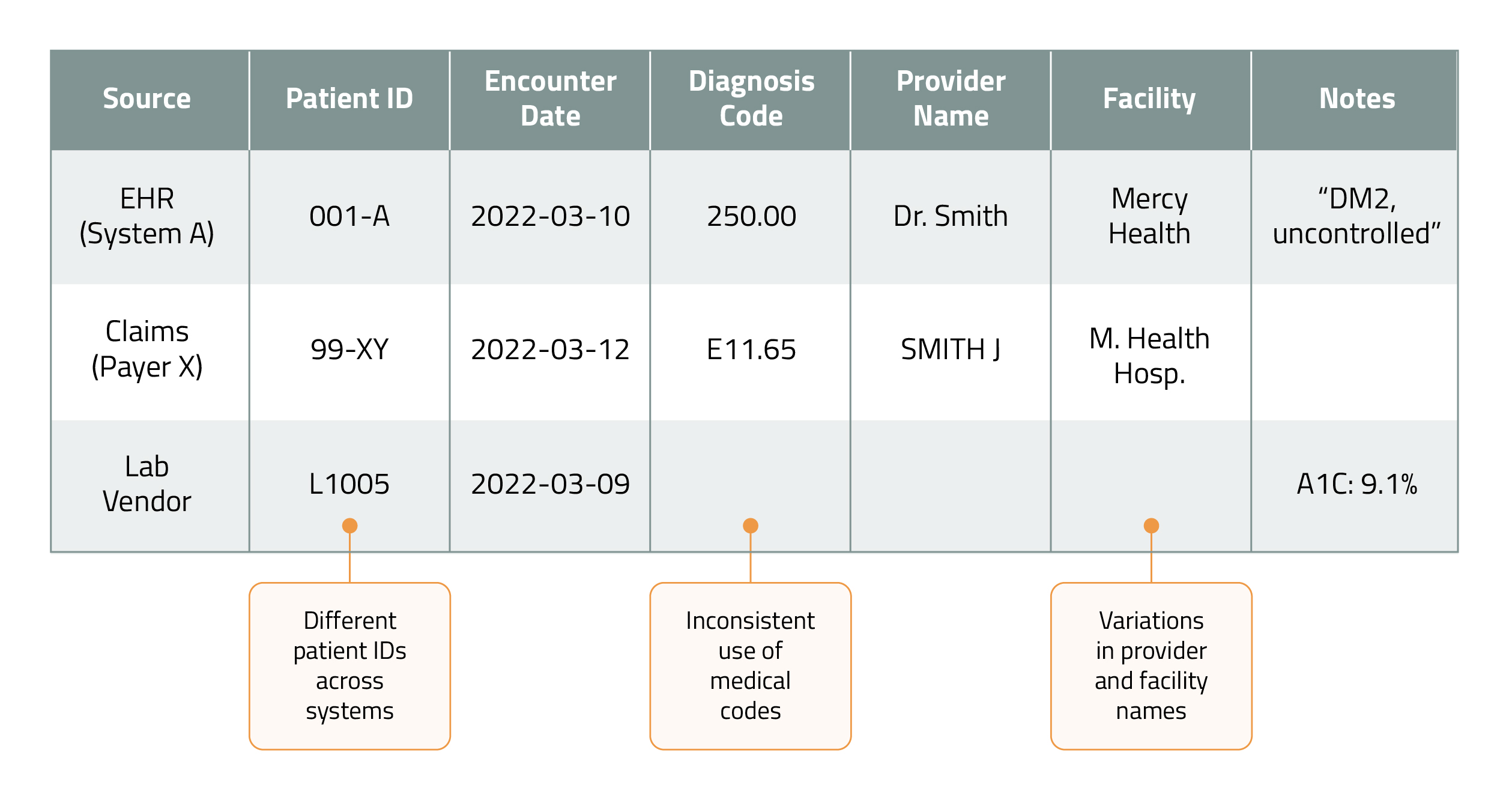
Nos let's take a look after the data was remastered.

Here is what was done to provide a more unified, enriched patient record.
Data remastering enables users to provide a more complete and accurate longitudinal patient journey and data that is ready for use in building AI/ML models. This can be accomplished and at the same time, greatly reduce manual reconciliation, saving weeks of analyst time and providing more confidence in the data and insights generated.
Address standardization is foundational in the data remastering process—especially in Healthcare and Life Sciences, where accurately linking entities like patients, providers, and facilities across disparate datasets is vital. In healthcare data, addresses appear across EHRs, claims, lab systems, referrals, billing, and more—often inconsistently.
Address standardization is the process of:
During the remastering process, standardizing addresses enables entity resolution and improves data quality in several ways:
1. Patient Identity Resolution
Matching the same patient across systems (e.g., EHR + claims or different health systems) requires accurate geographic data:
For example, "123 Main St., Apt 2B" and "123 Main Street #2B" may be two versions of the same address that need normalization to resolve as one patient.
2. Provider and Facility Matching
Facilities and provider groups may operate under different names or locations in different systems:
For example, "Mercy Health, 300 W 5th St" might also be listed as "MH - 5th Street Campus"—standardization resolves both to a single, consistent record.
3. Geo-Enrichment and Market Intelligence
Once addresses are standardized, they can be:
For Healthcare Providers and Life Sciences companies, geo-enrichment is used to understand patient migration patterns; to identify hotspots for treatment or even rare disease diagnoses, and to target providers based on their treatment and prescribing behaviors.
4. Data Quality & Regulatory Compliance
Inaccurate or inconsistent address data can among many things:

So what does address standardization look like from a remastering workflow?

As you can see, there are a number of elements that are normalized.
Data remastering isn’t just a data engineering task—it’s a strategic imperative. It unlocks AI, accelerates RWE, improves compliance, and makes your data scientists 10x more effective. If your team is spending more time cleaning than analyzing, it’s time to scale with purpose.
Kythera Labs' Wayfinder platform, built on Databricks, combines automated pipelines, AI/ML-based deduplication, and clinical context enrichment to make your data ready for the future of healthcare and life sciences. If you’d like to learn more, get in touch or reach out at LinkedIn.




