
La revista internacional The International Journal of Nonlinear Sciences and Numerical Simulation (IJNSNS) alcanzó en 2008 un índice de impacto de 8’91 y desde 2006 (hasta 2009) lidera la lista de revistas internacionales en el área de Matemática Aplicada del Journal Citation Reports (JCR). En 2011 ya no lo hará: IJNSNS ha cambiado de editorial (de Freund a De Gruiter) y su editor principal (Ji-Huan He) ha sido substituido (por Krishnaswamy Nandakumar). El making of del alto índice de impacto de IJNSNS, gracias a las malas artes de J.-H. He, nos lo explican Douglas N. Arnold y Kristine K. Fowler, «Nefarious Numbers,» Notices of the AMS 58: 434-437, Mach 2011 [ArXiv, 1 Oct 2010]. Más información en «Arnold & Fowler on “Nefarious Numbers” about the impact factor manipulation,» Francis’ world inside out, February 18, 2011. Esta entrada será mi primera participación en el Carnaval de Matemáticas 2.1 alojado por Tito Eliatrón Dixit.
Antes de nada hay que explicar la figura que abre esta entrada. El Consejo de Investigación Australiano (Australian Research Council, el equivalente australiano al CSIC español) ha evaluado mediante encuestas a investigadores la calidad de 20.000 revistas internacionales. La calidad global de una revista puede ser A* (lo mejor en su campo), A (de muy alta calidad), B (de reputación sólida) y C (para las que no encajan en las otras categorías). La lista ERA incluye 170 de las 175 revistas internacionales impactadas de la categoría «Mathematics, Applied» del JCR de 2008. La revista #1, IJNSNS ha sido calificada como B. Las revistas #2 y #3, Communications on Pure and Applied Mathematics (CPAM) y SIAM Review (SIREV), que solo alcanzan un índice impacto de 3’69 y 2’80, resp., son revistas de categoría A*. La línea roja en la figura se ha colocado en el percentil 20% para el índice de impacto de las revistas tipo A* (lo mejor de lo mejor); hay que destacar que 51% de las revistas tipo A tienen un índice de impacto mayor que este nivel, como el 23% de las revistas tipo B y el 17% de las «peores» revistas (tipo C). Obviamente, IJNSNS es el caso más anómalo. Su índice de impacto es astronómico para ser una revista de categoría B. Entre las 10 revistas con mayor índice de impacto (JCR 2008) tenemos 7 revistas A*, 2 revistas A y solo una revista B, IJNSNS. ¿Cómo es posible que IJNSNS haya obtenido un índice de impacto tan alto?
El índice de impacto se calcula como un cociente entre las citas recibidas y el número de artículos. En 2008 se citaron 821 veces los 79 artículos de IJNSNS publicados en 2007 y 561 veces los 84 publicados en 2006, por tanto, el índice de impacto es (821+561)/(79+84)=1382/163=8’479. ¿Cómo ha logrado Ji-Huan He que IJNSNS haya obtenido un índice de impacto tan alto?
El investigador que más citas a IJNSNS ha producido en 2008 es … su editor principal, Ji-Huan He (243 citas de las 1382). El segundo citador es D. D. Ganji (con 114 citas) y el tercero Mohamed El Naschie (con 58 citas), ambos son miembros del comité editorial de la revista. Estos 3 autores son responsables del 29% de las citas que cuentan para el índice de impacto de IJNSNS. Más aún, el 71’5% de las citas en 2008 a IJNSNS son citas a artículos publicados en 2006 y 2007 (las citas que cuentan para el índice de impacto).
La revista internacional que más ha citado a IJNSNS en 2008 es el Journal of Physics: Conference Series, responsable de 294 citas (más del 20% de las 1382). Todas estas citas provienen de un solo número de esta revista, las actas de un congreso internacional organizado por… Ji-Huan He, editor principal de IJNSNS en su propia universidad. La segunda revista que más ha citado a IJNSNS en 2008 fue el Topological Methods in Nonlinear Analysis, responsable de 206 citas (el 14%) y de nuevo todas las citas provienen de un solo número de esta revista, un número especial cuyo editor invitado es … como no, Ji-Huan He. La tercera revista más citadora en 2008 a IJNSNS es la revista Chaos, Solitons and Fractals, con 154 citas; Ji-Huan He era miembro del comité editorial de CS&F y su editor principal Mohamed El Naschie es coeditor (regional) de IJNSNS. La cuarta revista más citadora es el Journal of Polymer Engineering, también de un solo número y también editado por Ji-Huan He. Ji-Huan He es responsable «directo» de más del 50% de las citas al IJNSNS en 2008.
Según el Essential Science Indicators, producido por Thomson Reuters, J.-H. He es uno de los científicos más citados de la actualidad en Matemáticas, con 6.800 citas y un índice-h de 39 (según Hirsch, inventor del índice-h, la media de los ganadores del premio Nobel de Física es 35). He y sus malas artes han logrado encumbrarle al súmmun de los científicos más citados. Por ejemplo, sólo el número especial de la revista Journal of Physics: Conference Series antes citado, editado por él mismo, contiene 353 citas a sus propios artículos. ¡Qué os voy a contar!
En este blog ya nos hemos hecho eco en varias ocasiones de las malas prácticas de He: «El editor que se autoedita, buen autoeditor es (salvo que le corten la cabeza como a El Naschie),» 27 noviembre 2008; «El presidente de SIAM y la “ingeniería” del índice de impacto de revistas internacionales,» 12 diciembre 2009; y «Una broma de mal gusto del ISI Web of Science o esto va de castaño a oscuro,» 16 junio 2009.
Lo sorprendente es que hasta el año 2009 nadie se atrevía a criticar las malas artes de J.-H. He. Imperaba una ley del silencio que destaparon una serie de blogs y una serie de artículos que criticaron la «basura» He-siana (porque sus artículos técnicos son pura «basura» no hay mejor palabra para calificarlos). En este blog nos hemos hecho eco de ello en varias ocasiones: «La cruzada de Francisco M. Fernández contra Ji-Huan He y los He-sianos, un ejemplo de la “basura” que se publica en revistas “respetables”,» 5 febrero 2009; «Nueva cruzada contra los He-sianos, pero en revistas sin índice de impacto, por ahora,» 23 abril 2009; «Nuestro cruzado, Marcelo, logra uno de los artículos más descargados en ScienceDirect,» 7 octubre 2009; «Nuevos avatares de la cruzada anti-He-siana de la mano del nuevo cruzado Sir Jason, autor del blog “El Naschie Watch”,» 2 julio 2010; ; y «Nikolai Kudryashov y la cruzada en defensa de la fe en la matemática aplicada,» 27 noviembre 2010.
Hecha la ley, hecha la trampa. La ley de Goodhart nos dice que «cuando una medida se convierte en un objetivo, deja de ser una buena medida.» El
índice de impacto ha pasado de ser un indicador bibliométrico desconocido para la mayoría de los investigadores a convertirse en la medida de la calidad más utilizada para revistas, investigadores e instituciones científicas. La manipulación del índice de impacto es inevitable, aunque pocas veces es de forma tan exagerada como en el caso del IJNSNS cuando era editado por J.-H. He (yo espero que el nuevo editor le lave la cara a esta revista).
Goodhart’s law warns us that “when a measure becomes a target, it ceases to be a good measure.”





 de H indica que H artículos han recibido al menos H citas. Hirsch ha introducido varias variantes de su índice, la última es el índice
de H indica que H artículos han recibido al menos H citas. Hirsch ha introducido varias variantes de su índice, la última es el índice  (hbarra). Este índice vale N si el autor tiene N artículos que tienen al menos tantas citas como el índice
(hbarra). Este índice vale N si el autor tiene N artículos que tienen al menos tantas citas como el índice 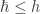 y para un autor sin coautores
y para un autor sin coautores 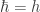 , aunque podría darse dicha igualdad incluso cuando hay coautores. Los artículos que se cuentan al calcular el índice
, aunque podría darse dicha igualdad incluso cuando hay coautores. Los artículos que se cuentan al calcular el índice 