

A última atualização importante para a especificação HTTP foi em 1999, tempo esse em que o RFC 2616 padronizou o HTTP 1.1 e introduziu tanto o suporte necessário para keep-alive e pipelining. Enquanto o HTTP 1.0 precisava rigorosamente do modelo “único pedido por conexão”, HTTP 1.1 reverteu esse comportamento: por padrão, um cliente e servidor HTTP 1.1 mantém a conexão aberta, a menos que o cliente indique o contrário (via cabeçalho Connection: close).
Por que se preocupar? Configurar uma conexão TCP é muito dispendioso! Mesmo em um caso otimizado, uma rota completa de um único caminho entre o cliente e o servidor pode demorar de 10 a 50ms. Agora multiplique isso três vezes para completar o handshake TCP, e já estamos vendo um teto de 150ms! O keep-alive nos permite reutilizar a mesma conexão entre pedidos diferentes e amortizar esse custo.
O único problema é, muitas vezes, como desenvolvedores, temos a tendência de esquecer isso. Dê uma olhada em seu próprio código, quantas vezes você reutilizou uma conexão HTTP? O mesmo problema é encontrado na maioria dos wrappers de API, e mesmo nas bibliotecas HTTP padrão da maioria das linguagens, que desabilitam o keep-alive por padrão.
HTTP pipelining
A boa notícia é que o keep-alive é suportado por todos os navegadores modernos e na maior parte trabalha de forma não convencional. Infelizmente, o suporte para pipelining não está tão bem na fita assim: nenhum navegador o suporta oficialmente, e poucos desenvolvedores pensam sobre isso. O que é lamentável, porque pode trazer benefícios significativos de desempenho!
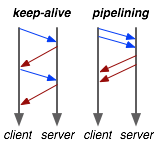
Enquanto o keep-alive nos ajuda a amortizar o custo de criação de uma conexão TCP, o pipelining nos permite quebrar o rigoroso modelo “enviar um pedido, aguarde resposta”. Em vez disso, podemos enviar várias solicitações, em paralelo, pela mesma conexão, sem esperar por uma resposta em forma de série. Isso pode parecer uma otimização menor no início, mas vamos considerar o seguinte cenário: pedido 1 e pedido 2 são feitos em pipeline, o pedido 1 leva 1.5s para renderizar no servidor, enquanto o pedido 2 leva 1s. Qual é o tempo total de execução?
É claro que a resposta depende da quantidade de dados enviados de volta, mas o limite inferior é, na verdade, 1.5s! Uma vez que os pedidos são feitos em pipeline, tanto o pedido 1 quanto o a pedido 2 podem ser processados pelo servidor em paralelo. Por isso, o pedido 2 é concluído antes do pedido 1, mas é enviado imediatamente após o pedido 1 estar completo. Menos conexões, tempos de resposta mais rápidos – faz você se perguntar por que ninguém anuncia que sua API suporta HTTP pipelining?
HTTP keep-alive & pipelining em Ruby
Infelizmente, muitas bibliotecas HTTP padrão revertem para HTTP 1.0: uma conexão, uma solicitação. A própria rede/http do Ruby usa um comportamento pouco conhecido, em que por padrão um cabeçalho “Connection: close” é acrescentado a cada pedido, exceto quando você está usando a forma de bloco:
require 'net/http'
start = Time.now
Net::HTTP.start('127.0.0.1', 9000) do |http|
r1 = http.get "/?delay=1.5"
r2 = http.get "/?delay=1.0"
p Time.now - start # => 2.5 - doh! keepalive, but no pipelining
end
Com o exemplo acima, a gente recebe os benefícios do keep-alive, mas infelizmente net/http não oferece suporte para pipelining. Para permitir isso, você vai ter que usar um net-http-pipeline, que é uma biblioteca independente:
require 'net/http/pipeline'
start = Time.now
Net::HTTP.start 'localhost', 9000 do |http|
http.pipelining = true
reqs = []
reqs << Net::HTTP::Get.new('/?delay=1.5')
reqs << Net::HTTP::Get.new('/?delay=1.0')
http.pipeline reqs do |res|
puts res.code
puts res.body[0..60].inspect
end
p Time.now - start # => 1.5 - keep-alive + pipelining!
end
EM-HTTP & Goliath: keep-alive + pipelining
Enquanto o pipelining é desativado na maioria dos navegadores, devido a muitas questões relacionadas com proxies e caches, ele não deixa de ser uma otimização útil, ou para falar com o seu parceiro de API. A boa notícia é que Apache, Nginx, HAProxy e outros o suportam, mas o problema é que a maioria dos servidores de aplicação, mesmo os que afirmam ser “HTTP 1.1”, geralmente não o suportam.
O suporte verdadeiro para keep-alive e pipelining é uma das razões pelas quais construímos em-http-request e Goliath para nossa pilha no PostRank. Um exemplo simples em ação:
require 'goliath'
class Echo < Goliath::API
use Goliath::Rack::Params
use Goliath::Rack::Validation::RequiredParam, {:key => 'delay'}
def response(env)
EM::Synchrony.sleep params['delay']
[200, {}, params['delay']]
end
end
require 'em-http-request'
EM.run do
conn = EM::HttpRequest.new('http://localhost:9000/')
start = Time.now
r1 = conn.get :query => {delay: 1.5}, :keepalive => true
r2 = conn.get :query => {delay: 1.0}
r2.callback do
p Time.now - start # => 1.5 - keep-alive + pipelining
EM.stop
end
end
O tempo de execução total é 1.5s. Se a sua API pública ou privada for construída em cima de HTTP, então keep-alive e pipelining são características que você deve aproveitar sempre que puder.
Otimizando HTTP: interrogue o seu código!
Veja slides aqui.
Enquanto nós amamos gastar tempo otimizando nossos algoritmos, ou tornando os bancos de dados mais rápidos, muitas vezes esquecemos o básico: a criação de conexões TCP é dispendiosa, e o pipelining pode levar a grandes vitórias. Você usa reutiliza as conexões HTTP em seu código? Será que o servidor do seu aplicação suporta pipelining? As respostas são geralmente “não, e eu não tenho certeza”, o que é algo que temos que mudar!
***
Artigo traduzido pela Redação iMasters, com autorização do autor. Publicado originalmente em http://www.igvita.com/2011/10/04/optimizing-http-keep-alive-and-pipelining/

De 0 a 10, o quanto você recomendaria este artigo para um amigo?