
The following is an excerpt from “The Data Journalism Handbook,” a collection of essays and resources covering the growing field of data journalism.
 In August 2010 some colleagues and I organised what we believe was one of the first international “data journalism” conferences, which took place in Amsterdam. At this time there wasn’t a great deal of discussion around this topic and there were only a couple of organizations that were widely known for their work in this area.
In August 2010 some colleagues and I organised what we believe was one of the first international “data journalism” conferences, which took place in Amsterdam. At this time there wasn’t a great deal of discussion around this topic and there were only a couple of organizations that were widely known for their work in this area.
The way that media organizations like Guardian and the New York Times handled the large amounts of data released by Wikileaks is one of the major steps that brought the term into prominence. Around that time the term started to enter into more widespread usage, alongside “computer-assisted reporting,” to describe how journalists were using data to improve their coverage and to augment in-depth investigations into a given topic.
Speaking to experienced data journalists and journalism scholars on Twitter it seems that one of the earliest formulations of what we now recognise as data journalism was in 2006 by Adrian Holovaty, founder of EveryBlock — an information service which enables users to find out what has been happening in their area, on their block. In his short essay “A fundamental way newspaper sites need to change,” he argues that journalists should publish structured, machine-readable data, alongside the traditional “big blob of text”:
“For example, say a newspaper has written a story about a local fire. Being able to read that story on a cell phone is fine and dandy. Hooray, technology! But what I really want to be able to do is explore the raw facts of that story, one by one, with layers of attribution, and an infrastructure for comparing the details of the fire — date, time, place, victims, fire station number, distance from fire department, names and years experience of firemen on the scene, time it took for firemen to arrive — with the details of previous fires. And subsequent fires, whenever they happen.”
But what makes this distinctive from other forms of journalism which use databases or computers? How — and to what extent — is data journalism different from other forms of journalism from the past?
“Computer-Assisted Reporting” and “Precision Journalism”
Using data to improve reportage and delivering structured (if not machine readable) information to the public has a long history. Perhaps most immediately relevant to what we now call data journalism is “computer-assisted reporting” or “CAR,” which was the first organised, systematic approach to using computers to collect and analyze data to improve the news.
CAR was first used in 1952 by CBS to predict the result of the presidential election. Since the 1960s, (mainly investigative, mainly U.S.-based) journalists, have sought to independently monitor power by analyzing databases of public records with scientific methods. Also known as “public service journalism,” advocates of these computer-assisted techniques have sought to reveal trends, debunk popular knowledge and reveal injustices perpetrated by public authorities and private corporations. For example, Philip Meyer tried to debunk received readings of the 1967 riots in Detroit — to show that it was not just less-educated Southerners who were participating. Bill Dedman’s “The Color of Money” stories in the 1980s revealed systemic racial bias in lending policies of major financial institutions. In his “What Went Wrong,” Steve Doig sought to analyze the damage patterns from Hurricane Andrew in the early 1990s, to understand the effect of flawed urban development policies and practices. Data-driven reporting has brought valuable public service, and has won journalists famous prizes.
In the early 1970s the term “precision journalism” was coined to describe this type of news-gathering: “the application of social and behavioral science research methods to the practice of journalism.” Precision journalism was envisioned to be practiced in mainstream media institutions by professionals trained in journalism and social sciences. It was born in response to “new journalism,” a form of journalism in which fiction techniques were applied to reporting. Meyer suggests that scientific techniques of data collection and analysis rather than literary techniques are what is needed for journalism to accomplish its search for objectivity and truth.
Precision journalism can be understood as a reaction to some of journalism’s commonly cited inadequacies and weaknesses: dependence on press releases (later described as “churnalism”), bias towards authoritative sources, and so on. These are seen by Meyer as stemming from a lack of application of information science techniques and scientific methods such as polls and public records. As practiced in the 1960s, precision journalism was used to represent marginal groups and their stories. According to Meyer:
“Precision journalism was a way to expand the tool kit of the reporter to make topics that were previously inaccessible, or only crudely accessible, subject to journalistic scrutiny. It was especially useful in giving a hearing to minority and dissident groups that were struggling for representation.”
An influential article published in the 1980s about the relationship between journalism and social science echoes current discourse around data journalism. The authors, two U.S. journalism professors, suggest that in the 1970s and 1980s the public’s understanding of what news is broadens from a narrower conception of “news events” to “situational reporting,” or reporting on social trends. By using databases of — for example — census data or survey data, journalists are able to “move beyond the reporting of specific, isolated events to providing a context which gives them meaning.”
As we might expect, the practise of using data to improve reportage goes back as far as “data” has been around. As Simon Rogers points out, the first example of data journalism at the Guardian dates from 1821. It is a leaked table of schools in Manchester listing the number of students who attended it and the costs per school. According to Rogers this helped to show for the first time the real number of students receiving free education, which was much higher than what official numbers showed.
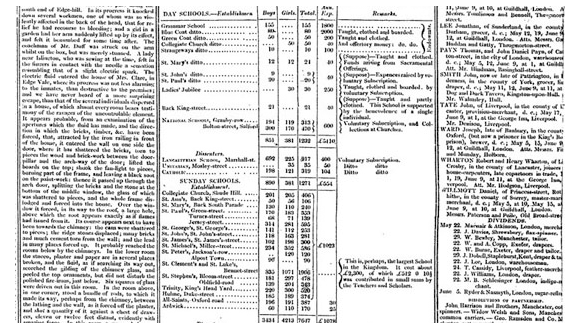
Data Journalism in the Guardian in 1821 (The Guardian)
Another early example in Europe is Florence Nightingale and her key report, “Mortality of the British Army,” published in 1858. In her report to the parliament she used graphics to advocate improvements in health services for the British army. The most famous is her “coxcomb,” a spiral of sections, each representing deaths per month, which highlighted that the vast majority of deaths were from preventable diseases rather than bullets.
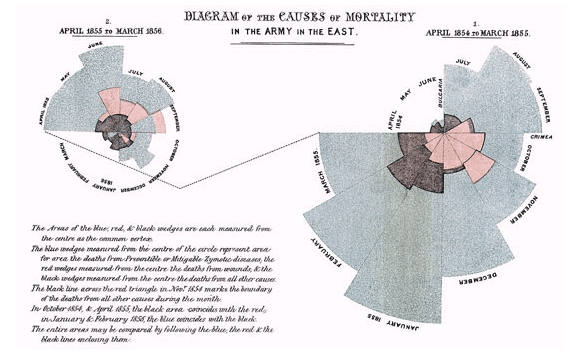
Mortality of the British Army by Florence Nightingale (Image from Wikipedia)
Data journalism and Computer-Assisted Reporting
At the moment there is a “continuity and change” debate going on around the label “data journalism” and its relationship with these previous journalistic practices which employ computational techniques to analyze datasets.
Some argue that there is a difference between CAR and data journalism. They say that CAR is a technique for gathering and analyzing data as a way of enhancing (usually investigative) reportage, whereas data journalism pays attention to the way that data sits within the whole journalistic workflow. In this sense data journalism pays as much — and sometimes more — attention to the data itself, rather than using data simply as a means to find or enhance stories. Hence we find the Guardian Datablog or the Texas Tribune publishing datasets alongside stories, or even just datasets by themselves for people to analyze and explore.
Another difference is that in the past investigative reporters would suffer from a poverty of information relating to a question they were trying to answer or an issue that they were trying to address. While this is of course still the case, there is also an overwhelming abundance of information that journalists don’t necessarily know what to do with. They don’t know how to get value out of data. A recent example is the Combined Online Information System, the U.K.’s biggest database of spending information — which was long sought after by transparency advocates, but which baffled and stumped many journalists upon its release. As Philip Meyer recently wrote to me: “When information was scarce, most of our efforts were devoted to hunting and gathering. Now that information is abundant, processing is more important.”
On the other hand, some argue that there is no meaningful difference between data journalism and computer-assisted reporting. It is by now common sense that even the most recent media practices have histories, as well as something new in them. Rather than debating whether or not data journalism is completely novel, a more fruitful position would be to consider it as part of a longer tradition, but responding to new circumstances and conditions. Even if there might not be a difference in goals and techniques, the emergence of the label “data journalism” at the beginning of the century indicates a new phase wherein the sheer volume of data that is freely available online combined with sophisticated user-centric tools, self-publishing and crowdsourcing tools enables more people to work with more data more easily than ever before.
Data journalism is about mass data literacy
Digital technologies and the web are fundamentally changing the way information is published. Data journalism is one part in the ecosystem of tools and practices that have sprung up around data sites and services. Quoting and sharing source materials is in the nature of the hyperlink structure of the web and the way we are accustomed to navigate information today. Going further back, the principle that sits at the foundation of the hyperlinked structure of the web is the citation principle used in academic works. Quoting and sharing the source materials and the data behind the story is one of the basic ways in which data journalism can improve journalism, what Wikileaks founder Julian Assange calls “scientific journalism.”
By enabling anyone to drill down into data sources and find information that is relevant to them, as well as to verify assertions and challenge commonly received assumptions, data journalism effectively represents the mass democratisation of resources, tools, techniques and methodologies that were previously used by specialists — whether investigative reporters, social scientists, statisticians, analysts or other experts. While currently quoting and linking to data sources is particular to data journalism, we are moving towards a world in which data is seamlessly integrated into the fabric of media. Data journalists have an important role in helping to lower the barriers to understanding and interrogating data, and increasing the data literacy of their readers on a mass scale.
At the moment the nascent community of people who called themselves data journalists is largely distinct from the more mature CAR community. Hopefully in the future we will see stronger ties between these two communities, in much the same way that we see new NGOs and citizen media organizations like ProPublica and the Bureau of Investigative Journalism work hand in hand with traditional news media on investigations. While the data journalism community might have more innovative ways of delivering data and presenting stories, the deeply analytical and critical approach of the CAR community is something that data journalism could certainly learn from.
This excerpt was lightly edited. Links were added for EveryBlock, the Guardian Datablog, Texas Tribune datasets, the Combined Online Information System, and Julian Assange’s reference to “scientific journalism.”
 The Data Journalism Handbook (Early Release) — This collaborative book aims to answer questions like: Where can I find data? What tools can I use? How can I find stories in data? (The digital Early Release edition includes raw and unedited content. You’ll receive updates when significant changes are made, as well as the final ebook version.)
The Data Journalism Handbook (Early Release) — This collaborative book aims to answer questions like: Where can I find data? What tools can I use? How can I find stories in data? (The digital Early Release edition includes raw and unedited content. You’ll receive updates when significant changes are made, as well as the final ebook version.)
Related: