
:quality(80)/p7i.vogel.de/wcms/d1/4f/d14f0c11fbf6e5d56fdfeb16437e7048/0115479470.jpeg "Multi-Cloud-Management ermöglicht es Unternehmen, verschiedene Cloud-Dienste effizient zu integrieren und zu verwalten für verbesserte Flexibilität, Risikominimierung und Kosteneffizienz. (Bild: Rawpixel.com - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/b8/61/b8615878dfcb9b7383269a429384a593/0115304715.jpeg "Von klassischem Filesharing bis hin zu vollumfänglichen Collaboration-Plattformen: Dank Cloud Content Management haben Angestellte jederzeit sicheren Zugriff auf alle nötigen Daten und Anwendungen. (© greenbutterfly - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/3d/98/3d98b69e471f34ee67173e2b19150983/0115412594.jpeg "Enterprise-SaaS-Angebote bringen die klassischen Geschäftsanwendungen in die Cloud – und damit hohe Flexibilität und Skalierbarkeit, um im Wettbewerb langfristig am Ball zu bleiben. (Bild: peacehunter - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/de/86/de860f6849e0da6d124b6733fbae9f2f/0117807293.jpeg "Barrierefreie Cloud-Services – eine Einführung in das Thema rund um das Barrierefreiheitsstärkungsgesetz (BFSG), das ab dem 29. Juni 2025 für viele Unternehmen verpflichtend sein wird. (Bild: © Vitalii Vodolazskyi - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/8a/b3/8ab361c0aa8f6268832881464f23a529/0117615533.jpeg "Nur 27 Prozent der Frauen im Technologiesektor geben an, dass sie mit ihrer Arbeit sehr zufrieden sind. (Bild: © Angelo/peopleimages.com – stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/89/0e/890e6d131e5e270b3929be52654aac59/0117400623.jpeg "Augmented Reality Cloud: über die reale Welt gelegter interaktiver und persistenter Digital-Layer. (Bild: frei lizenziert © Gerd Altmann)")
:quality(80)/p7i.vogel.de/wcms/97/87/978722e74c36c9a70077a34ab1c9ace9/0117955536.jpeg "IntegrityNext hilft mit einer neuen Plattform bei der Bewältigung der CBAM-Vorgaben der EU. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/47/f7/47f704e3d2d3a3bc6e0112536682ea37/0117562533.jpeg "Proxmox bietet sich als Open-Source-Alternative zu VMware-Produkten an, Dienstleister Vshosting als Unterstützung beim Umstieg. (Bild: frei lizenziert: Alex Barcley )")
:quality(80)/p7i.vogel.de/wcms/12/b5/12b52290dc4baec972ff23c236646af5/0118069583.jpeg "Alexander Wallner verantwortet ab Anfang Mai das Deutschland- und Zentraleuropa-Geschäft des CRM-Anbieters Salesforce. (Bild: Plusserver)")
:quality(80)/p7i.vogel.de/wcms/f6/48/f6488bdcf1ec7ea7d4c2cdbf606836b8/0117933962.jpeg "Ceyoniq hat Version 9.2 seiner Informationsplattform nscale veröffentlicht (Bild: Ceyoniq)")
:quality(80)/p7i.vogel.de/wcms/67/fc/67fc87866965a0ed5c704085cd1dbb18/0117992232.jpeg "Microsoft bringt mit Windows 11 24H2 einen neuen Teams-Client. (Bild: Joos - Microsoft)")
:quality(80)/p7i.vogel.de/wcms/d9/43/d94301179f8b1e9ffa61f7aeca9bc2da/0117501722.jpeg "All for One Group führt mit dem Rise One Service Center eine neue Lösung für SAP ERP in der Cloud ein. (Bild: sean - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/17/b7/17b7b5c26b88818bcc7969589e912496/0117613806.jpeg "Die generative KI-Lösung Microsoft Copilot for Security unterstützt Sicherheits- und IT-Experten. (Bild: pinkeyes - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/74/15/74156625be02fe9ade8e116a45522c59/0118053590.jpeg "In Deutschland bewegt sich der Mangel an Fachkräften auf Rekordniveau, bei 149.000 Stellen fehlt eine Besetzung. Wie sollten Unternehmen mit der Situation umgehen? Und welche Rolle spielt IT-Outsourcing als intelligente Lösung in diesem Zusammenhang? (Bild: © Negro Elkha - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/96/a5/96a5b97e49976a351a89ac03f3db1390/0118107882.jpeg "Dr. Jürgen Hernichel übernimmt als Geschäftsführer die Rolle des Interim-CEO bei Plusserver. (Bild: © Ralf Baumgarten für Plusserver)")
:quality(80)/p7i.vogel.de/wcms/2f/72/2f72fa06f3c347f39eb2c8394668bef8/0118047783.jpeg "Die Gründe, warum sich Cloud-Migrationen schwierig gestalten, sind oft nicht auf den ersten Blick zu erkennen. (Bild: fran_kie - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/46/4f/464f9874393542fda430ec285f3c0c65/0117931419.jpeg "Lacework hat seine Enterprise-Funktionen ausgebaut und sorgt dafür, dass Sicherheitsexperten die nötigen Informationen schnell und verständlich aufbereitet erhalten. (Bild: Screenshot / Lacework)")
:quality(80)/p7i.vogel.de/wcms/ec/e8/ece8b409d6a81bebed4f2371a42b054e/0117932238.jpeg "Wie sich Cloud-Infrastrukturen entwickeln – und was dies für die Security bedeutet. (Bild: © kanpisut - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/02/e0/02e02be7aae78d444104e3424d8b95fc/0117904124.jpeg "Unternehmen sollten interne IT-Sicherheit beliebter und verständlicher machen; das Sicherheitsbewusstsein der Mitarbeiter entscheidet letztendlich über die wahre Stärke der IT-Abwehr. (Bild: zephyr_p - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/71/ab/71ab1e5c80cb2e89643ce54481ac4f41/0117883495.jpeg "Phishing-Angriffe, Identitätsdiebstahl oder Datenmissbrauch: Cyberversicherungen versprechen Schutz gegen Risiken im Netz. (Bild: frei lizenziert Mohamed Hassan - Pixabay)")
:quality(80)/p7i.vogel.de/wcms/1d/5f/1d5ff604e768dc07af9d7a5e934aac13/0117587541.jpeg "Data Protection ist eine in Unternehmen oft vernachlässigte Disziplin, dabei aber unheimlich wichtig, um SaaS-Anwendungsdaten zu sichern und auch wiederherstellen zu können. (Bild: duncanandison - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/30/3d/303dee95ed8a8c2ffe1df16ad1b6f371/0117576672.jpeg "Copilot bietet in Microsoft 365 umfangreiche Möglichkeiten. Dazu gehören auch neue Funktionen in OneDrive, Teams und SharePoint. (Bild: Microsoft)")
:quality(80)/p7i.vogel.de/wcms/85/a7/85a7e47314bd1ff01cd0ef3dab86d088/0117440139.jpeg "Verfügen Sicherheitsteams nicht über den notwendigen Einblick in alle Daten, die ihr Netzwerk passieren, setzen sie sich einem hohen, sehr kostspieligen Sicherheitsrisiko aus. (Bild: Borin - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/a3/22/a322cb08846922fbb3ff2ff456088565/0117584477.jpeg "Viele Cloud-Speicherdienste bieten sicheres Datenspeichermanagement und den flexiblen Zugriff auf Dokumente und Dateien. (Bild: Jacky - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/b7/b3/b7b39f210afdbde0b94af77adf75e1cc/0116951275.jpeg "Sage Copilot stellt Kleinunternehmern, CFOs und Buchhaltern einen digitalen Assistenten als Teammitglied zur Seite, mit dem sie in natürlicher Sprache interagieren können. (Bild: Sage)")
:quality(80)/p7i.vogel.de/wcms/bf/7e/bf7ecbbfd3a815ad7160b3fcfc4eb847/0117775397.jpeg "Eine aktuelle AWS-Studie zeigt, dass sich Cloud und KI in Unternehmen durchsetzen. Dennoch gilt es zahlreiche Hindernisse zu überwinden. (Bild: frei lizenziert)")
:quality(80)/p7i.vogel.de/wcms/09/73/097302aa1b7e01683424de334a8a56a8/0117567518.jpeg "War die im Koalitionsvertrag verankerte Open-Source-Förderung doch nur ein Lippenbekenntnis? (Bild: Tuomas Kujansuu - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/4a/f9/4af97680066d2bdf0f21aef50ff77703/0117543337.jpeg "Um den Datenschutz zu verbessern, ist es in Nextcloud jetzt möglich, eigene Large Language Models (LLM) zu verwenden, so dass Anwender bei der Verwendung von KI-Funktionen keine Daten unbeabsichtigt ins Internet senden. (Bild: LukaszDesign - stock.adobe.com)")
Wo sind all die Dienste hin? Worauf es bei Cloud-Ausfällen ankommt
Flexibel, skalierbar und kostengünstig: Die Dienste der Cloud-Giganten wie Amazon, Google oder Microsoft haben hunderttauende Kunden in Europa überzeugt. Aber was passiert, wenn deren Cloud-Infrastruktur ausfällt?
Anbieter zum Thema
Die Cloud ist in den meisten deutschen Firmen Alltag. So nutzen 75 Prozent der deutschen Unternehmen einen Provider, 67 Prozent haben bereits zwei und 42 Prozent sogar drei Cloud-Dienstleister unter Vertrag. Dies zeigt die Truth in Cloud Studie von Veritas. Die Dienstleister haben zurecht einen ausgezeichneten Ruf, was die Verfügbarkeit ihrer Dienste betrifft. In den vergangenen Jahren sind ihre Dienste nur sehr selten und dann nur kurz komplett ausgefallen. Trotzdem bleibt ein Restrisiko, das umso stärker ins Gewicht fällt, je wichtiger die Dienste der Unternehmen sind, die auf der Cloud laufen. Es ist deshalb wichtig, dass IT-Verantwortliche wissen und verstehen, wo Gefahren lauern und wo die Verantwortlichkeiten liegen.
Die Provider selbst handeln nach einem Shared Responsibility Modell, bei dem immer ein Teil der Verantwortung beim Kunden liegt. So bleibt der Kunde immer für seine Daten und deren Compliance verantwortlich. Werden Daten korrumpiert oder gehen verloren, liegt die Verantwortung aufseiten der Kunden, diese aus einem eigenen Backup zu rekonstruieren.
:quality(80)/images.vogel.de/vogelonline/bdb/1454100/1454113/original.jpg "Die Anatomie eines typischen Cloud-Ausfalls und die Auswirkungen auf den Betrieb.")
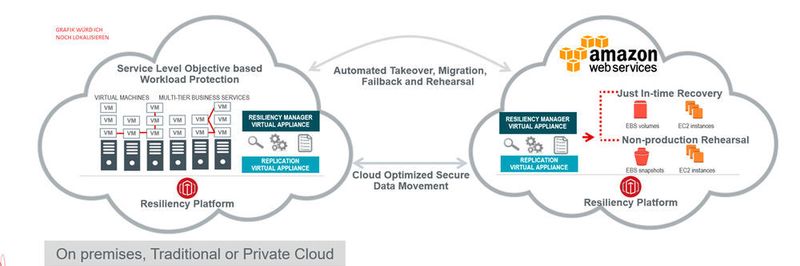
:quality(80)/images.vogel.de/vogelonline/bdb/1454100/1454114/original.jpg "Veritas bietet mti der Resiliency Platform umfangreiche Disaster Recovery-Möglichkeiten auch für Multi-Cloud-Umgebungen.")
:quality(80)/images.vogel.de/vogelonline/bdb/1454100/1454115/original.jpg "Wer kontrolliert was?Die Abbildung zeigt ein Shared-Responsible-Modell auf Microsoft Azure.")
Das ist auf Firmenseite noch zu wenig in den Köpfen mancher IT-Leiter verankert, denn weitere Ergebnisse der Veritas Studie zeigen: 83 Prozent der deutschen Firmen, die IaaS nutzen oder dies planen, sehen die Verantwortung für Datensicherung in der Cloud bei den Cloud Service Providern. Und 69 Prozent sind fest überzeugt, dass sie die Verantwortung für Datensicherheit, Datenschutz und Compliance an ihre Cloud Service Provider delegieren können. Wer mit den Daten seinen Teil der Verantwortung in die Cloud schiebt, ist für den Ernstfall schlecht oder gar nicht vorbereitet.
Auch in Fragen der Hochverfügbarkeit ist manchem IT-Leiter nicht klar, was die Cloud Provider abdecken und was ein Unternehmen selbst tun muss. So geben die Public-Cloud-Dienstleister klare und strenge Garantien für ihre Service Level ab, diese beziehen sich aber meistens nur auf die Verfügbarkeit der Infrastruktur in der Cloud. Fällt sie aus, müssen die Provider sie wieder zum Laufen bringen. Doch danach liegt es an Kunden, die darauf laufenden Dienste und Anwendungen selbst wieder in Betrieb zu nehmen. Je komplexer die Anwendungen strukturiert sind und je mehr Daten während des Ausfalls verloren gehen, desto länger wird die Wiederherstellung der kritischen Applikationen dauern. Oft nutzen die IT-Abteilungen für diese Aufgabe isolierte Tools und manuelle Prozesse, ohne Automatismen. Da geht im Ernstfall wertvolle Zeit verloren, die sich dann in teurer Downtime der wichtigen Dienste manifestiert.
Testen im laufenden Betrieb
Die Wiederherstellung der Daten und Dienste nach einem Cloud-Ausfall ist dann schwer beherrschbar und wird unkalkulierbar. IT-Leiter können ein klares Zeichen setzen, wenn sie diese wichtigen Prozesse professionalisieren. Für diesen Zweck gibt es Lösungsansätze wie die Business-Continuity-Plattofrm „Resiliency Platform“ von Veritas. Sie helfen dabei, mehrstufige Applikationsarchitekturen und ihre Verfügbarkeit rund um die Uhr zu kontrollieren, den Ausfallprozess zu testen und den Failover-Prozess im Ernstfall mit einem Mausklick automatisch und kontrolliert abzuwickeln.
Solche Konzepte müssen sich eng an die Infrastruktur der führenden Cloud-Anbieter ankoppeln, um nahtlos von einer Cloud-Infrastruktur auf eine andere oder auf ein lokales Rechenzentrum des Kunden umschalten zu können. Dafür nutzen sie deren Protokolle, Dienste und Data Mover und sind von den wichtigen Cloud Providern entsprechend zertifiziert. Sie sind daher auch in der Lage, die Struktur der Applikationen sowohl on premises als auch in der Cloud automatisch und mit geringer Fehlerquote per Autodiscovery zu erfassen, zu verstehen und die zu sichernden Applikations-Elemente so zu identifizieren. Die IT-Abteilung wird entlastet und es ist weniger wahrscheinlich, dass ein essenzieller Teil einer mehrstufigen Applikation übersehen wird.
Die Ergebnisse der Autodiscovery laufen in einer zentralen grafischen Oberfläche und einem Dashbard zusammen. Dort kann der IT-Verantwortliche, die Ergebnisse des gesamten Disaster-Recovery-Prozesses überblicken und per Drag & Drop modellieren. Im nächsten Schritt kann er einen großen Vorteil einer solchen übergreifenden Instanz ausspielen – das Testen des gesamten Vorgangs, ohne den Betrieb zu stören.
Per Mausklick lassen sich belastbare Werte in der Praxis ermitteln, wie lange der gesamte Umschaltprozess dauert, wie viele Produktiv-Daten verloren gehen. Der Ernstfall wird auf einmal berechenbar und kalkulierbar. Den zweiten großen Vorteil spielen solche Business-Continuity-Plattformen dann im Ernstfall aus – ihren Automatismus, der in der Krisensituation den komplexen Failover-Prozess automatisch abwickelt, und zwar nach den vorher im Test gemessenen Kriterien für die Dauer und die Menge der Daten, die während der Umschaltzeit verloren gehen könnten. IT-Leiter wissen nun, wie lange es dauert, wichtige Geschäftsanwendungen wiederherzustellen. Denn sie können mit Werten, die unter realen Bedingungen ermittelt wurden, den Ernstfall beschreiben.
Wissen was zu tun ist
Es ist gut , wenn IT-Leiter die Folgen eines Cloud-Ausfalls genau verstehen und sich darüber im Klaren sind, dass die Wiederherstellung nach dem Ausfall nur gemeinsam mit dem Cloud Service Provider zu stemmen ist. Richten Unternehmen für ihre Anwendungen bereits im Vorfeld entsprechende Ausfallmechanismen für die Multi-Cloud ein, haben sie im Ernstfall nicht nur die volle Verantwortung, sondern auch die volle Kontrolle über die Wiederherstellung ihrer kritischen Services. So reduziert der IT-Leiter Ausfallzeiten, einen Vertrauensverlust auf Kundenseite und damit finanzielle Schäden.
Der Autor: Mathias Wenig, Senior Manager TS und Digital Transformation Specialist bei Veritas.
(ID:45494931)
:quality(80)/p7i.vogel.de/wcms/fc/01/fc0186fed72bc69651035193ea05f0d6/0113956601.jpeg "Damit der Ausfall bei einem Cloud-Dienst nicht zum totalen Datenverlust für den Kunden wird, sollten Unternehmen ihre Daten immer auch in eigener Verantwortung zusätzlich sichern. (Bild: artiemedvedev - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/d4/74/d4744e6e123eddb17f942e84d2bedbdb/0116340305.jpeg "Mit Hilfe von Machine Learning und Künstlicher Intelligenz werden Backups sicherer. (Bild: ©peshkov, Getty Images via Canva.com)")