Honeycomb combines the raw accuracy of log aggregators, the speed of time series metrics, and the flexibility of APM (application performance metrics) to provide the world's first truly next-generation analytics service. Originally modeled off of Facebook's Scuba data platform, it has spun off to become an intuitive, delightful tool for exploring every part of your stack, from debugging slow queries to db internals, from application code to the network stack, to deep security dives.
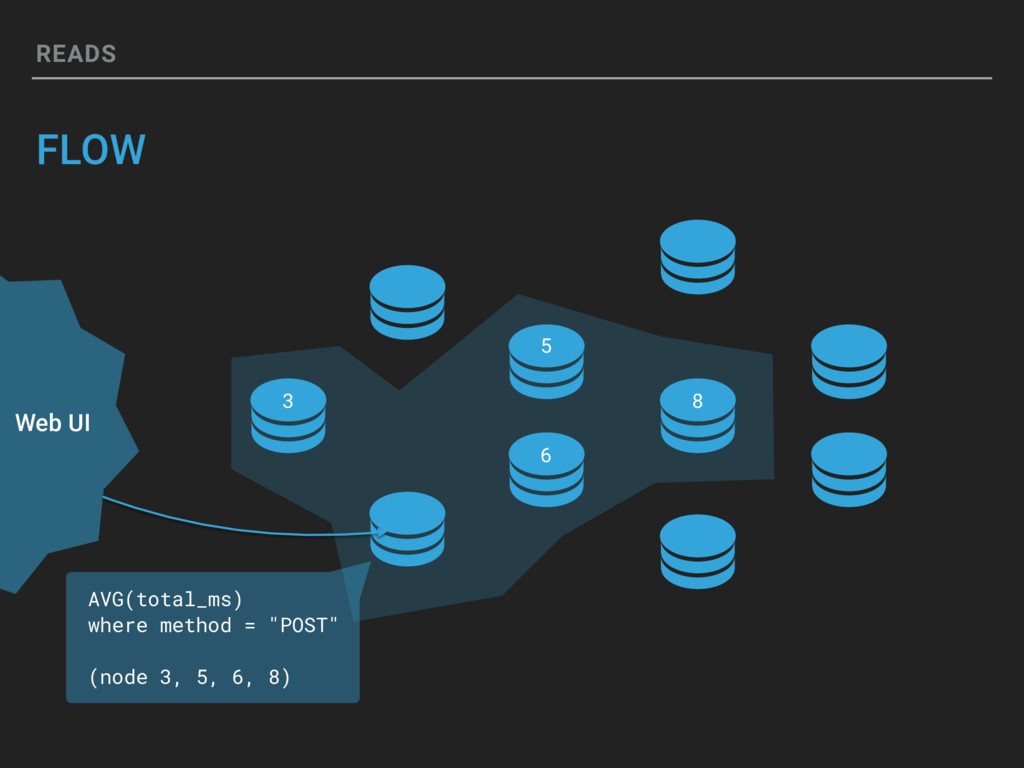
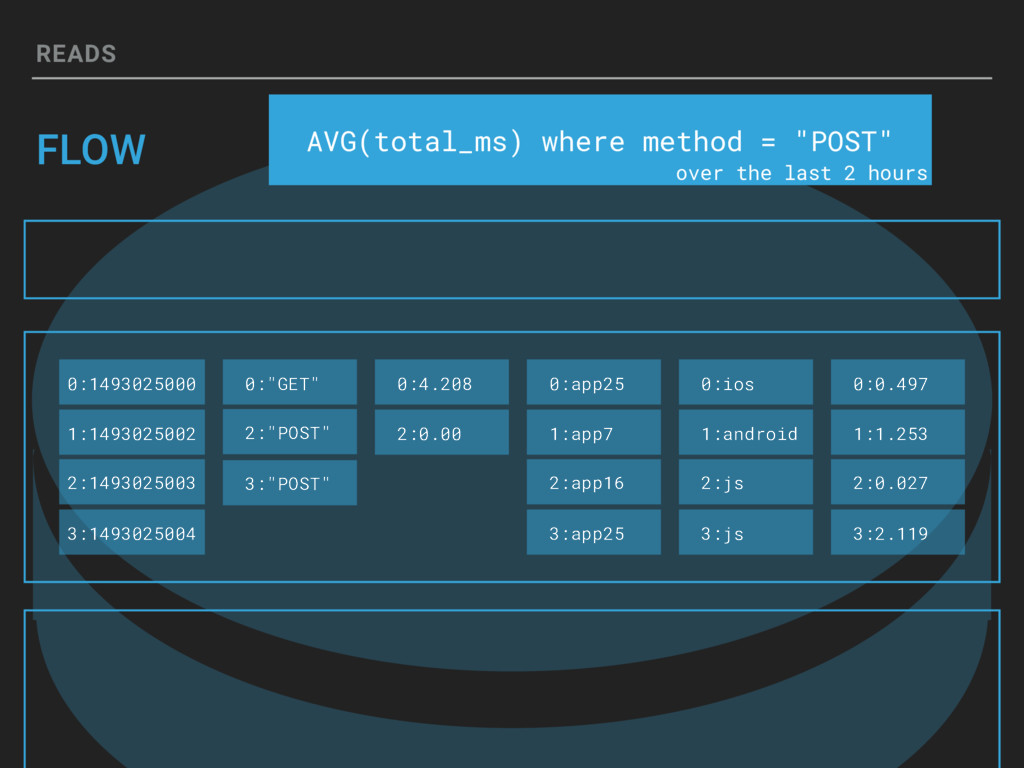
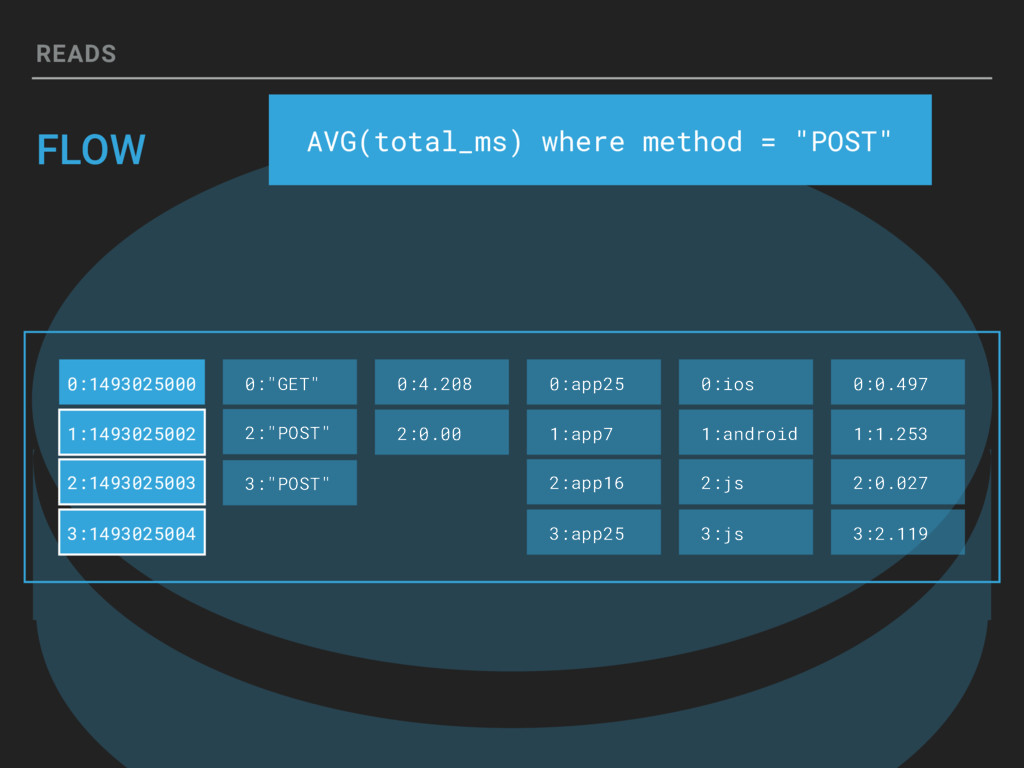
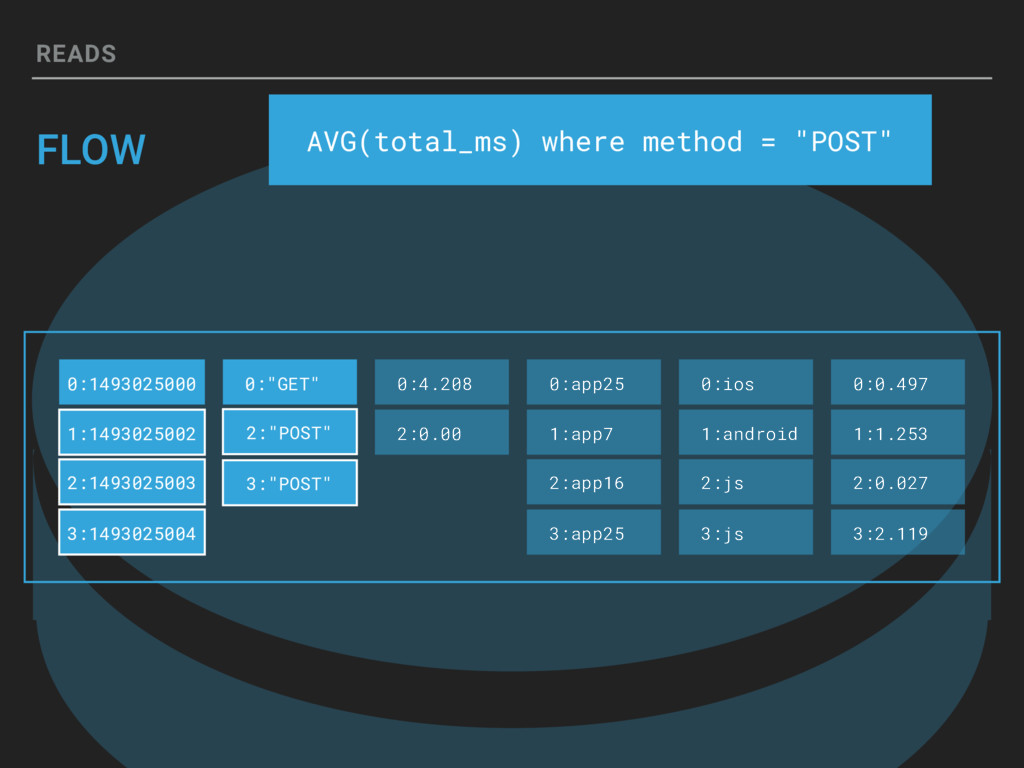
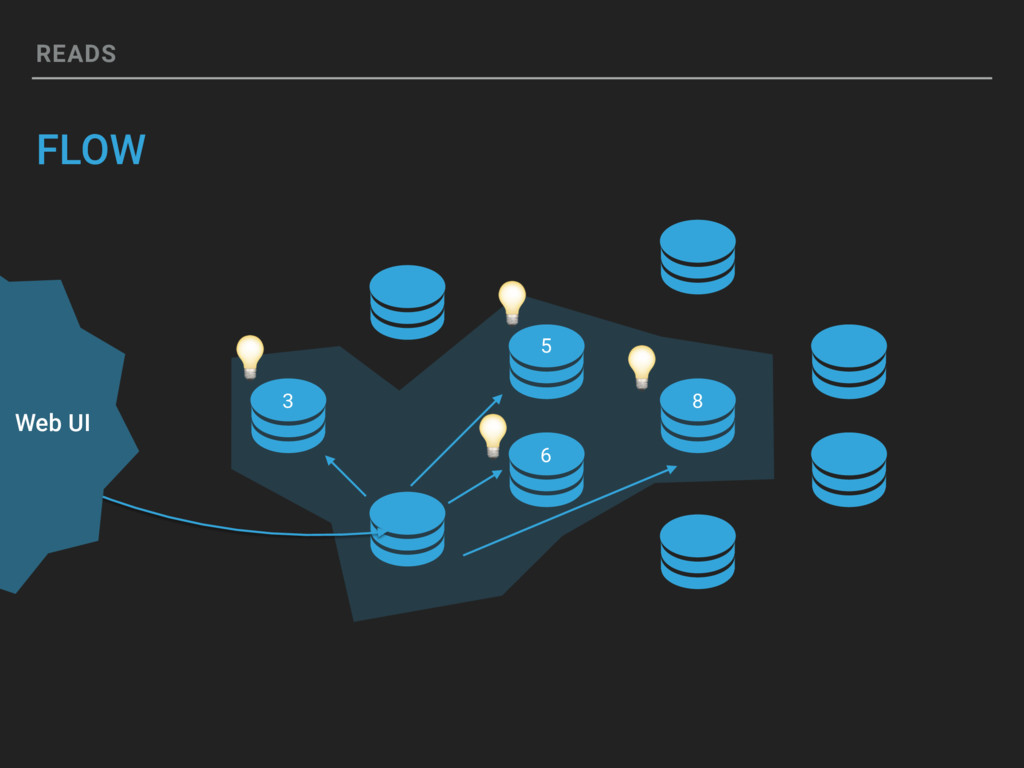
If you can represent it in a structured data event, Honeycomb can let you slice and dice in real-time. Honeycomb supports arbitrarily wide events and lets you query on as many attributes as you want. Come learn how Honeycomb is designed, from the custom-built column store up to the fan-out query model. Our mission is to make Honeycomb the tool that helps everyone be as good as the best debugger on your team, but this session will be a deep dive under the hood into how it really works, tradeoffs, deals with the devil and all.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
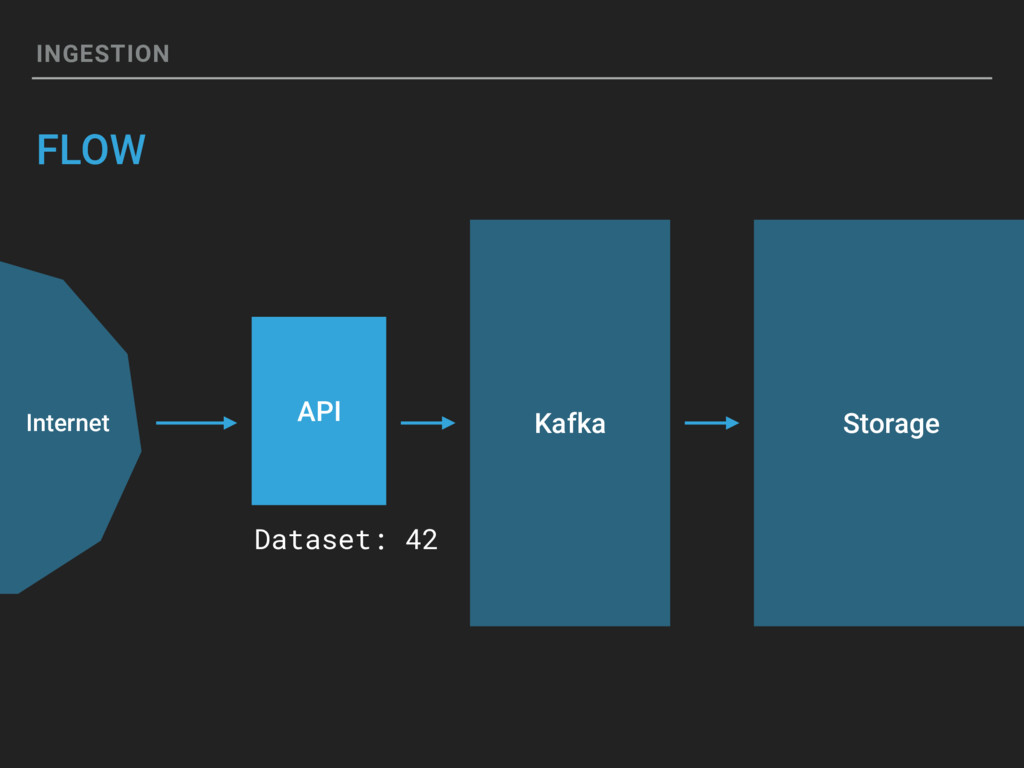{kind=link}
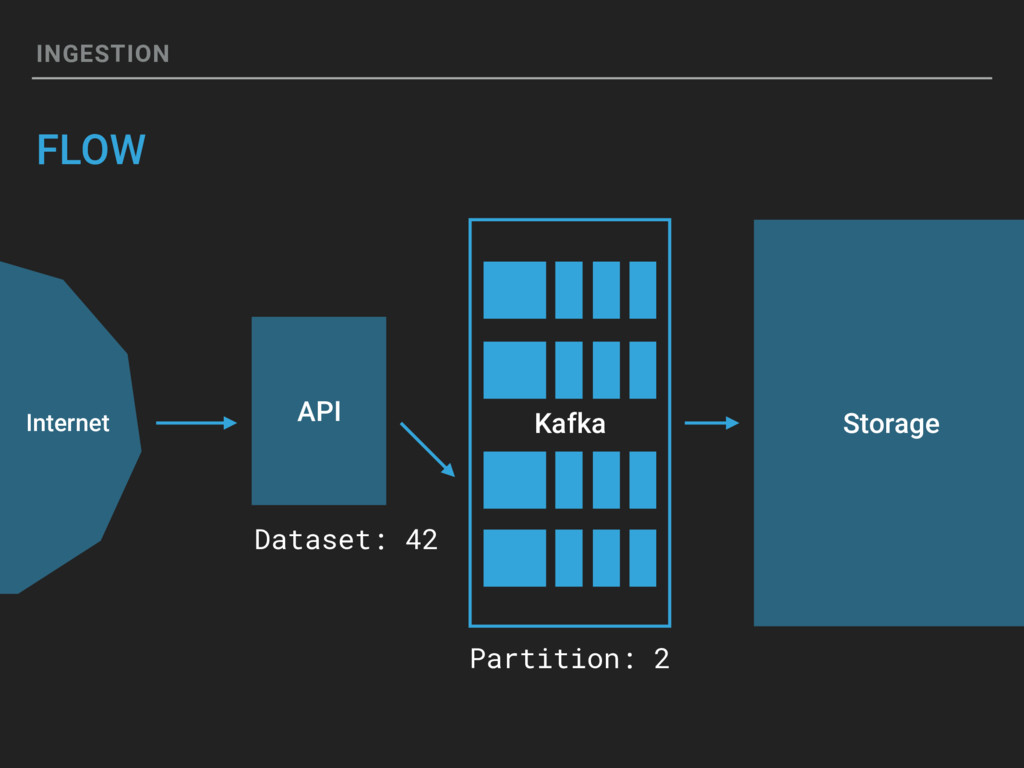{kind=link}
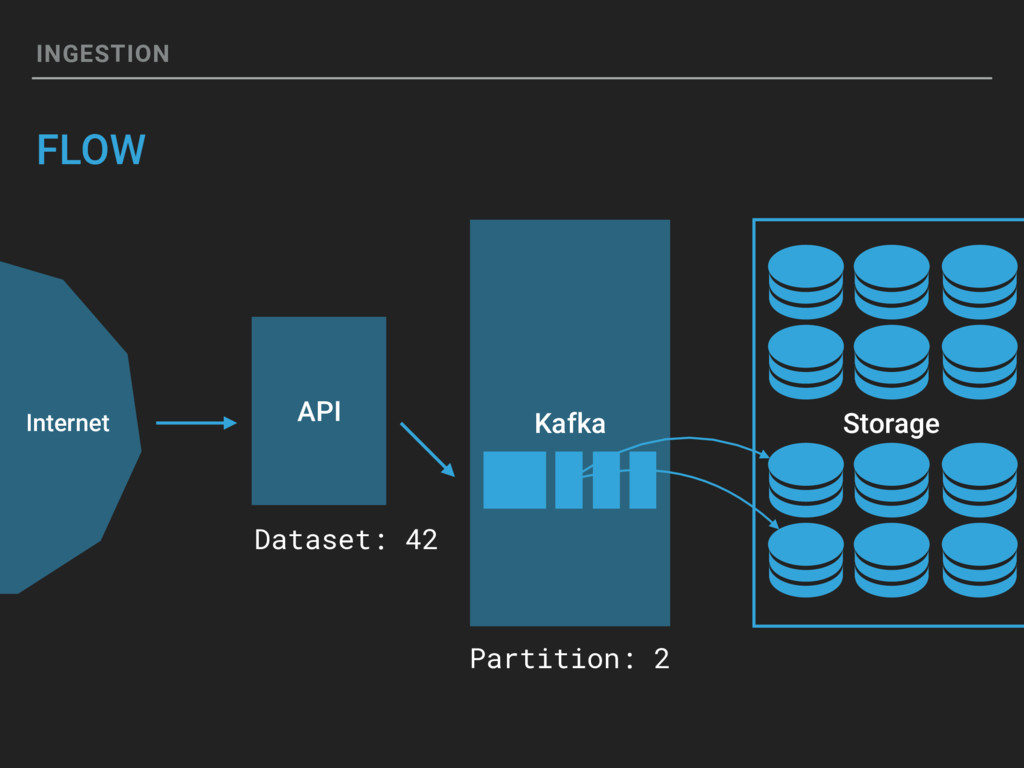{kind=link}
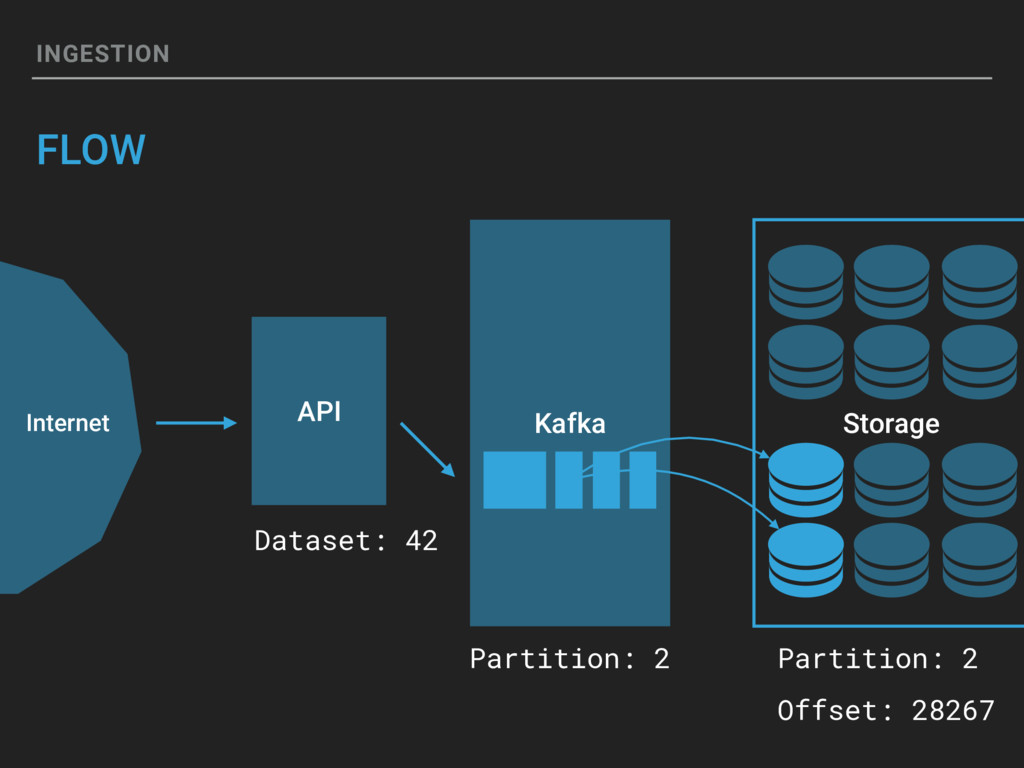{kind=link}
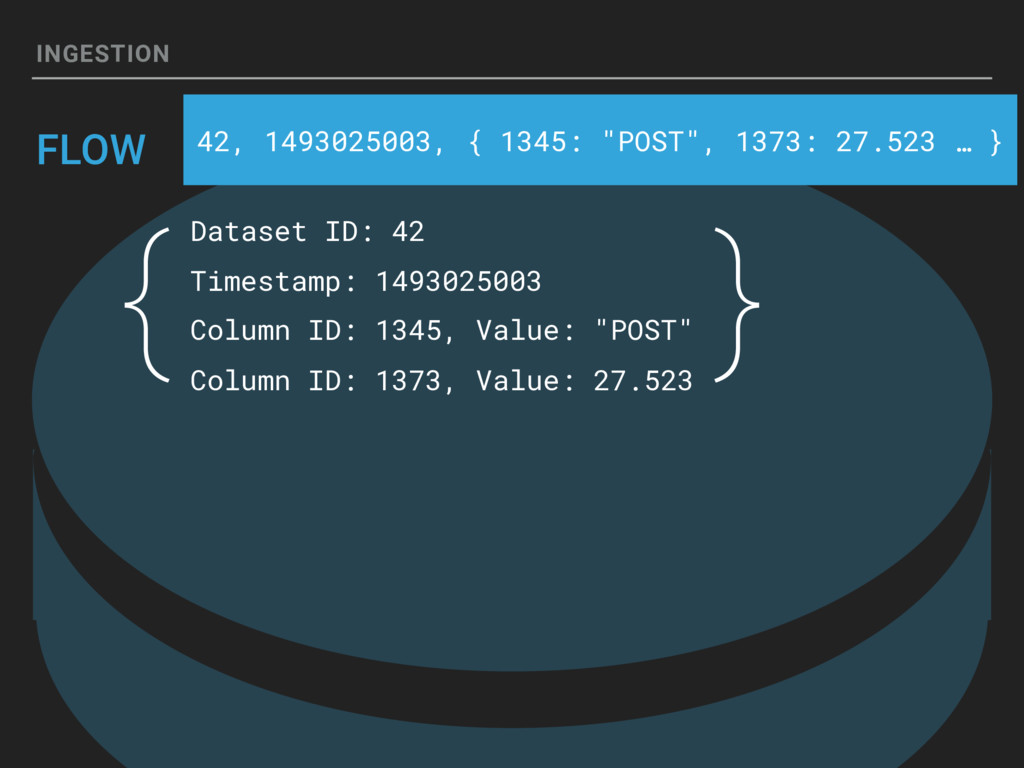{kind=link}
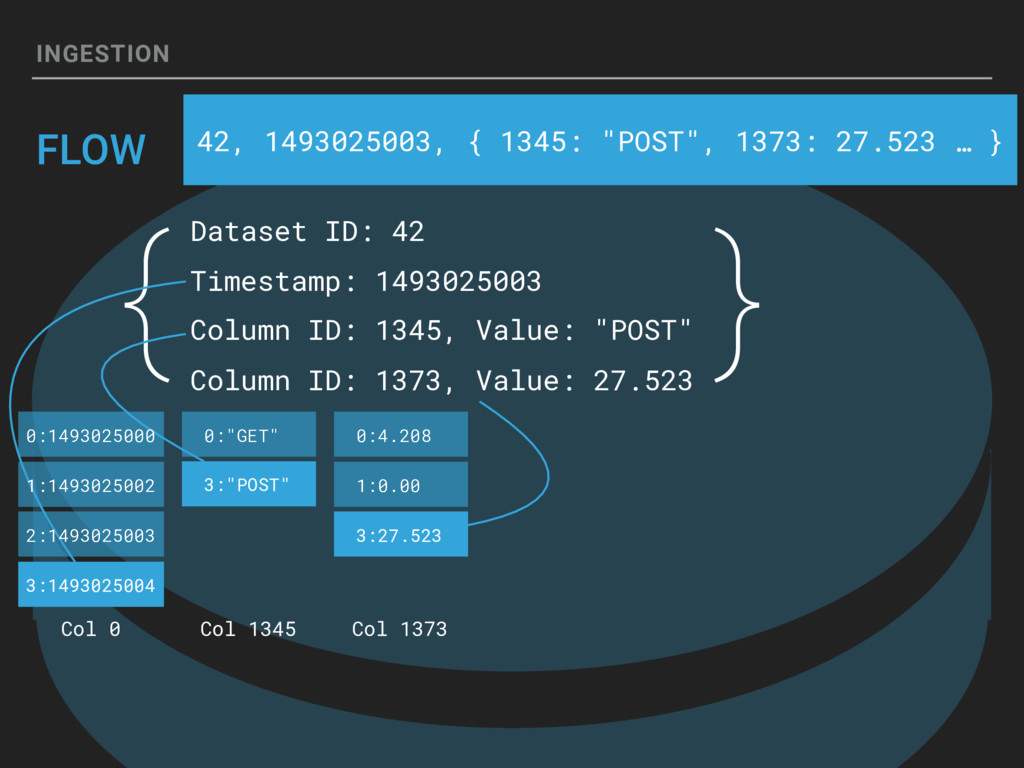{kind=link}
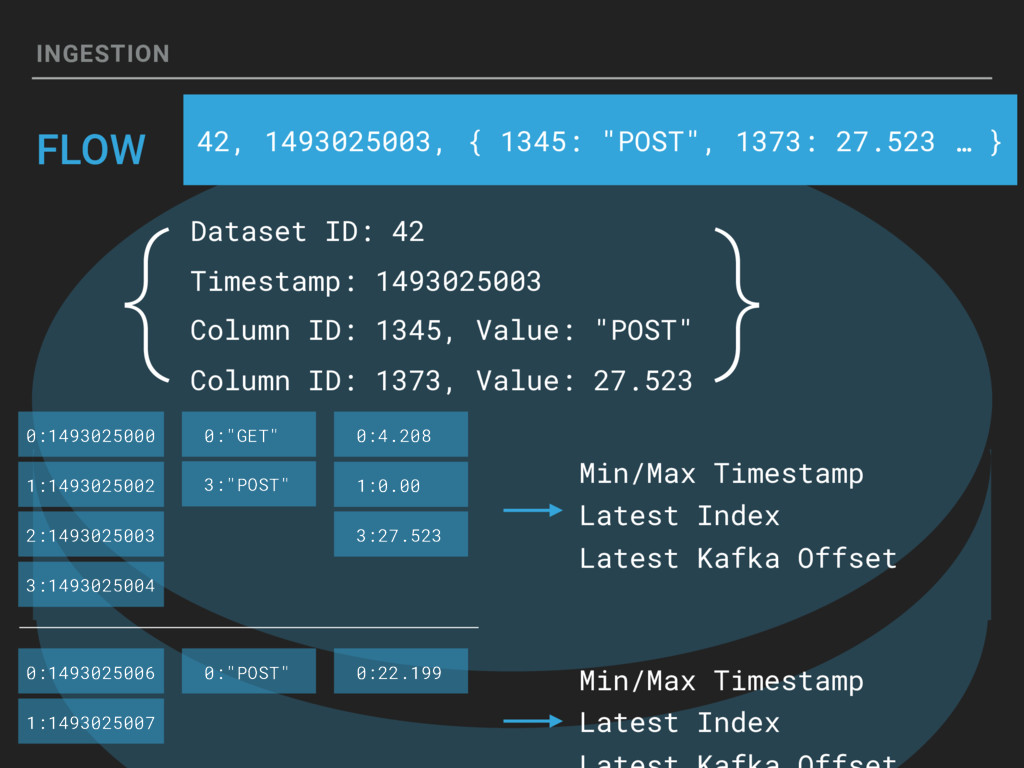{kind=link}
{kind=link}
{kind=link}
{kind=link}
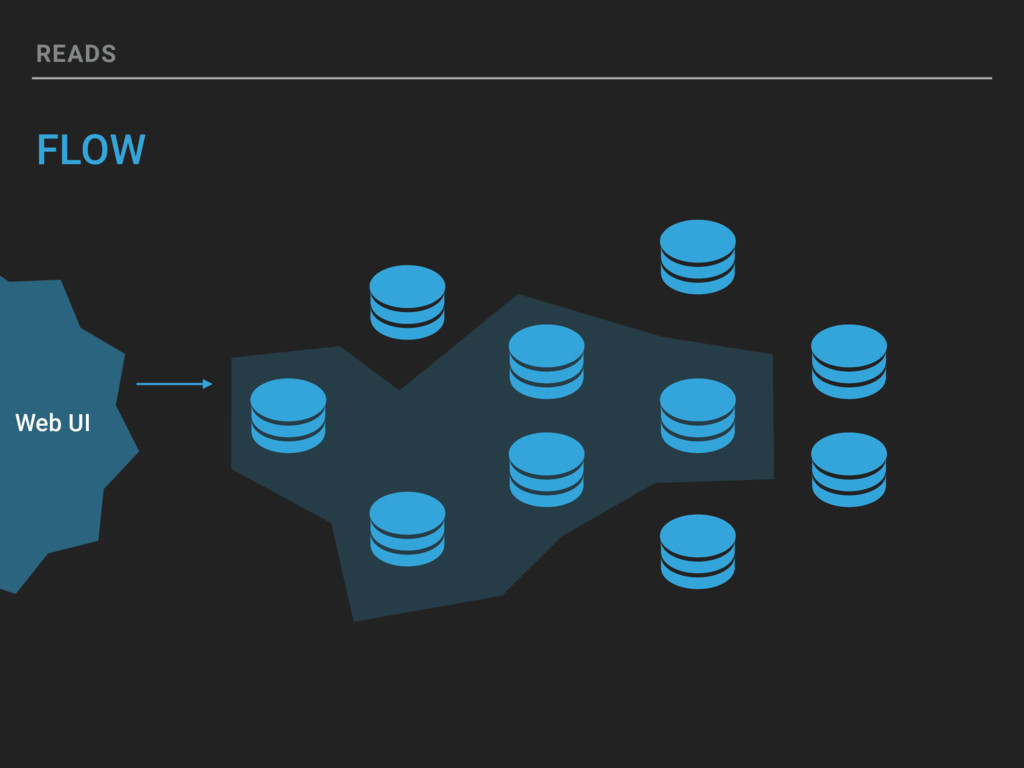{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}