
:quality(80)/p7i.vogel.de/wcms/c8/6b/c86bfadc9400e3859e5a8173b99872db/0114956871.jpeg "Für das große Gewinnerbild standen dann alle Preisträgerinnen und Preisträger noch einmal gemeinsam mit Moderatorin Margit Lievertz und Dev-Insider-Chefredakteur Stephan Augsten auf der Bühne. (Bild: krassevideos.de / VIT)")
:quality(80)/p7i.vogel.de/wcms/82/e2/82e20061fab6f1fc0561f023c6bfd2cc/0114109627.jpeg "Dev-Insider verleiht heute die IT-Awards 2023 in sechs Kategorien. (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/5f/f4/5ff47683e4bc8de6cf2d484e627c58f2/0107845613.jpeg "Wir präsentieren die Gewinnerinnen und Gewinner der Dev-Insider Readers’ Choice Awards, (Bild: VIT)")
:quality(80)/p7i.vogel.de/wcms/55/d8/55d8de7a538dd09179a73c8038cf4147/0107796204.jpeg "Zum achten Mal verleihen die Insider-Portale die IT-Awards, nach zwei virtuellen Events wieder im Rahmen einer Abendgala. (Bild: Vogel IT-Medien)")
:quality(80)/p7i.vogel.de/wcms/e5/77/e577580786af65fcc8627ff28480156c/0117746777.jpeg "Unternehmen müssen Schwachstellen innerhalb ihrer Software-Lieferketten erkennen und beseitigen. (Bild: © lucadp – stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/1c/99/1c994939fe7b0dadbb5c6116ed3d14c6/0117769807.jpeg "Durch verständliche Sprache werden komplexe Vorgänge klar und nachvollziehbar. Repräsentative Umfragen zeigen, dass Menschen Organisationen mehr vertrauen, die auf Fachsprache verzichten. (© Alextanya - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/ec/4f/ec4fbf78f6f68e7265dfdbbe4667ffda/0117729006.jpeg "Durch das jüngste Update zählt Wind River Studio Developer nunmehr fünf Module, die unabhängig voneinander bereitgestellt werden können. (Bild: Wind River)")
:quality(80)/p7i.vogel.de/wcms/21/cf/21cfe3098edfebfdfc0d6fde095d705e/0116987592.jpeg "Die SPDX-Arbeitsgruppe ist ein Projekt der Linux Foundation. (Bild: spdx.dev)")
:quality(80)/p7i.vogel.de/wcms/ce/e1/cee1ed439aa4f707ea03af6ef4fb0fb8/0117478744.jpeg "Google Workspace wird mit Google Gemini erweitert. Auch Endanwender profitieren dadurch. (Bild: Google)")
:quality(80)/p7i.vogel.de/wcms/3e/f6/3ef650209116833e59eb26c9c5ada534/0115274382.jpeg "Weg vom starren Systemdesign: Eine Continuous Architecture soll für mehr Flexibilität in der Software-Entwicklung sorgen. (Bild: <u><a href=https://unsplash.com/de/@and_machines>and machines</a></u>)")
:quality(80)/p7i.vogel.de/wcms/40/72/40725045e823b3b6f419c524cdefb522/0117624759.jpeg "Regelmäßig müssen IT-Verantwortliche bereits über die digitale Erfahrung berichten. (Bild: Cisco AppDynamics)")
:quality(80)/p7i.vogel.de/wcms/d9/f4/d9f4887ab7d9ed551c3b105d94e32f4f/0117258175.jpeg "Es braucht nur einen Auslöser, eine Beschreibung, was dann passiert, und schon laufen die Prozesse in der 'Event-driven Automation" von „Red Hat Ansible“. (Bild: Leigh Prather - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/bb/4c/bb4ca87eaa161f8d2734760f70df39c5/0117746985.jpeg "GenAI-Referenzarchitektur mit Google Cloud, Vertex AI, Gemini und Neo4j. (Bild: Neo4j)")
:quality(80)/p7i.vogel.de/wcms/d0/29/d02943e127505f666f93261918fd6305/0117304875.jpeg "Zig ist eine systemorientierte Sprache, die es einfacher machen möchte, sicheren und korrekten Code zu schreiben. (Bild: <u><a href=https://ziglang.org/>Ziglang.org</a></u>)")
:quality(80)/p7i.vogel.de/wcms/b1/13/b1138372998f1248fe18150065ae9a3a/0117574348.jpeg "Der Kurs „Rust Fundamentals“ von HighTec und Doulos ist als viertägige Präsenzveranstaltung oder als fünftägiges Remote-Live-Training geplant. (Bild: HighTec)")
:quality(80)/p7i.vogel.de/wcms/e5/39/e539bca18a629a40a77a8d8d8ce3f327/0117223910.jpeg "Wer eine nachhaltigere Software-Architektur nutzen will, muss früh im Engineering-Prozess ein paar grundlegende Entscheidungen zur Struktur und Konzeption terffen. (Bild: FrankBoston - stock.adobe.com)")
![Mithilfe eines anderen Konsensverfahrens, Hashgraph, ließe sich eine Menge CO2 bei der Berechnung von Kryptowährungen sparen. (Bild: Benjamin ['O°] Zweig - stock.adobe.com)](https://cdn1.vogel.de/annR7MKBLjg3UGu-x3l6Nvb7-fI=/288x162/smart/filters:format(jpg):quality(80)/p7i.vogel.de/wcms/4e/40/4e40e5356b18ebce4656f2a51e65c815/0116079923.jpeg "Mithilfe eines anderen Konsensverfahrens, Hashgraph, ließe sich eine Menge CO2 bei der Berechnung von Kryptowährungen sparen. (Bild: Benjamin ['O°] Zweig - stock.adobe.com)")
:quality(80)/p7i.vogel.de/wcms/01/d0/01d02743d019010886e4fe0d47222d72/0115628204.jpeg "Der Autor Fabian Tröltzsch auf der w3.vision X DMEXCO 2023. (© koelnmesse)")
:quality(80)/p7i.vogel.de/wcms/7a/59/7a595755b165e6d0939b52bc4bb82e9d/0113646230.jpeg "Blockchain-Technologien schaffen Vertrauen, was auch beim programmatischer Werbung von Vorteil ist. (Bild: <a href=https://pixabay.com/de/users/kiquebg-5133331/>kiquebg</a>)")
:quality(80)/p7i.vogel.de/wcms/af/ba/afba059e1e635289905bc63ce8cc4579/0117149678.jpeg "On-Premise bezeichnet den Betrieb von Software auf selbstverwalteten Hardware-Ressourcen. (Bild: <u><a href=https://unsplash.com/de/@tvick>Taylor Vick</a></u>)")
:quality(80)/p7i.vogel.de/wcms/79/8a/798ac0bb2a4e3a384a3c7634dc919ceb/0117709235.jpeg "APIs ermöglichen es verschiedenen Software-Anwendungen, Daten auszutauschen und miteinander zu interagieren, ohne dass Details zu Implementierung bekannt sein müssen. (Bild: <u><a href=https://pixabay.com/users/geralt-9301/>Gerd Altmann</a></u>)")
:quality(80)/p7i.vogel.de/wcms/ef/83/ef83b21f59d76ece1f76070d93e9bd6b/0116763715.jpeg "Mit der Verbreitung von generativer KI wird die Bedeutung von Software-Bots weiter zunehmen. (Bild: <u><a href=https://pixabay.com/users/alexandra_koch-621802/>Alexandra Koch</a></u>)")
:quality(80)/p7i.vogel.de/wcms/cb/53/cb53c867cfed49b9fe3f1bb1878e6f7a/0117096265.jpeg "Mit der Entwicklung neuer Technologien auf Echtzeitbasis werden Datenströme weiter an Bedeutung gewinnen. (Bild: <u><a href=https://unsplash.com/@sortino>Joshua Sortino</a></u>)")
:quality(80)/p7i.vogel.de/wcms/c2/21/c2213857722c33ef3d02db0acf33abc0/0112236476.jpeg "So sehen Chiselled Ubuntu containers aus – zumindest nach Auffassung der generativen KI DALL-E2. (Bild: Dall-E 2)")
:quality(80)/p7i.vogel.de/wcms/a9/6d/a96d15ff02a35fc84a9b65702395aa6b/0110694349.jpeg "Größenvergleich der gängigen Basis-Images (komprimiert und unkomprimiert). (Bild: Canonical)")
:quality(80)/p7i.vogel.de/wcms/ce/c1/cec146c6f112e79b71c56d37ee27145e/0105884802.jpeg "Das AWS Step Functions Workflow Studio ist ein visueller Editor, der sich insbesondere für das Prototyping von Workflows eignet. (Bild: Amazon Web Services)")
Tools und Workflows zur Datenspeicherung in der Cloud, Teil 5 Metadaten-Index für einen Data Lake in AWS
Um Daten in einem S3-basierten Data Lake sinnvoll durchsuchen zu können, müssen diese im Moment des Hinzufügens indiziert werden. Mit serverlosen Lambda-Funktionen lässt sich so ein Vorgang automatisieren. Für den eigentlichen Index verwenden wir eine DynamoDB-Datenbank, weil diese hochverfügbar ist und Zugriffszeiten im unteren Millisekundenbereich ermöglicht.
Anbieter zum Thema
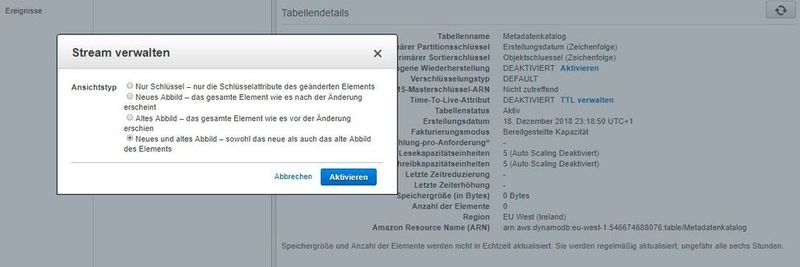

Zur Aufnahme unseres Index erstellen wir in der DynamoDB-Konsole eine neue DynamoDB-Tabelle mit dem Namen „Metadatenkatalog“, einem Primärschlüssel vom Typ Zeichenfolge (String) mit dem Namen „Erstellungsdatum“ und einem Sortierschlüssel vom Typ Zeichenfolge mit dem Namen „Objektschluessel“.
Anschließend klicken wir im „Übersicht“-Tab der neu erstellten Tabelle im Abschnitt „Stream Details“ auf „Stream verwalten“. Was hat es damit auf sich? Viele Anwendungen können zum Zeitpunkt einer Änderung von dieser Funktion „zum Erfassen der Änderungen an den in einer DynamoDB-Tabelle gespeicherten Elementen“ profitieren. Das Feature DynamoDB Streams erfasst eine zeitlich geordnete Abfolge von Änderungen auf Element-Ebene in jeder beliebigen DynamoDB-Tabelle und speichert diese Informationen bis zu 24 Stunden in einem Protokoll. Anwendungen können auf dieses Protokoll zugreifen und die Datenelemente vor und nach der Änderung nahezu in Echtzeit aufrufen.

Ein DynamoDB-Stream ist also ein strukturierter Informationsfluss zu/über Element-Änderungen in einer Amazon-DynamoDB-Tabelle. Aktiviert der Nutzer den Stream für eine bestehende Tabelle, werden von DynamoDB Informationen über jede Änderung an den Datenelementen in der Tabelle erfasst. Hierbei müssen wir uns für einen „Ansichtstyp“ entscheiden. Der Ansichtstyp steuert, welche Daten an den Stream gesendet werden. Wir konfigurieren ihn so, dass sowohl alte als auch neue Werte gesendet werden, wenn Daten aktualisiert werden.
Event-Logik mit Lambda
Sind die Vorbereitungen soweit abgeschlossen, könnte man beispielsweise zwei AWS-Lambda-Funktionen erstellen. Die Erste soll immer dann, wenn neue Datenobjekte im S3-Datenspeicher erstellt werden die zugehörigen Objektmetadaten in die eben erstelle DynamoDB-Tabelle schreiben. Sobald das erfolgt, könnte eine zweite Lambda-Funktion dafür sorgen, das Element im Amazon Elasticsearch Service zu veröffentlichen.
Zum Testen der Verarbeitungsketten mit Echtzeitdaten verwenden wir in unserem Beispiel ein vorbereitetes Twitterstorm-Dataset, dass wir in S3 bereitsellen. Ein kleines Python-Skript in einer EC2-Instanz erzeugt dann einen kontinuierlichen Datenstrom mit Test-Twitterposts. Die Business-Logik ist nicht in erster Linie Ziel dieses Beitrages. Dieser soll nur das Zusammenwirken der beteiligten AWS-Komponenten zeigen.
Stellen wir also nun eine AWS-Lambda-Funktion bereit, die ausgelöst wird, wenn Datenobjekte im Amazon S3-Bucket erstellt werden. Die Lambda-Funktion erfasst und veröffentlicht ein Element in der DynamoDB-Tabelle mit einer Reihe von Attributen, die sich auf die Metadaten beziehen. Wir erstellen die Lambda-Funktion in der Lambda-Konsole „from scratch“, also ohne Verwendung von Blueprints.
Im Beispiel verwenden wir als Runtime „Python 2.7“; die benötigte Rolle (hier „Lab1-LambdaExecutionRole“) haben wie zuvor erzeugt. Sie erlaubt der assoziierten Lambda-Funktion im Großen und Ganzen den Zugriff auf CloudWatch (Logs, Events, Alarme), S3, DynamoDB, Datapipeline, SNS, das Auflisten von Rollen in IAM.

Unsere in Python geschriebene Lambda-Funktion heißt im Beispiel “Lab1-S3ToDynamoDB.py. Der Code muss im Code-Editor eingefügt werden. Der Funktions-Name wird ohne die Endung „py“ eingetragen. Demnach ist in der Lambda-Console im Abschnitt „Function code“ bei „Runtime“ ebenfalls „Python 2.7“ auszuwählen und der „Handler“ hört auf dem Namen „lambda_function.lambda:handler“, wobei der Teil nach dem Punkt dem „Funktionsnamen“ unten entspricht.
Die Funktion führt im Wesentlichen folgende Schritte aus:
- Ermitteln des Bucket-Namen und des Objekt-Keys für das erstelle Objekt, das die Lambda-Funktion ausgelöst hat.
- Erstellen eines DynamoDB-Eintrages „über“ dieses S3-Objekt.
- Eintragen des Items in die DynamoDB-Tabelle
Im Abschnitt „Grundlegende Einstellungen“ legen wir noch eine einfache „Beschreibung“ fest, z. B. „S3 to DynamoDB“. Beim Arbeitsspeicher und beim Timeout übernehmen wir der Einfachheit halber die Default-Einstellung. Fehlt nur noch der Trigger. Wir klicken zur Sicherheit aber zunächst noch rechts oben auf „Speichern“.

Im oberen Teil der Lambda-Console fügen wir nun den gewünschten Trigger, in diesem Fall „S3“ ein. Dessen Konfiguration erfolgt im Abschnitt „Auslöser konfigurieren“ gleich unterhalb des Navigationsbaums für „Auslöser hinzufügen“. Hier geben wir das zu überwachende S3-Bucket an und als Ereignistyp „Alles Objekterstellungsereignisse“. Danach klickt man unten rechts auf „Hinzufügen“, was gerne übersehen wird. Rechts der Trigger-Konfiguration sieht man übrigens die Ressourcen, auf die die Rolle Zugriff hat; diese entsprechen den oben erwähnten Richtlinien der unterliegenden Rolle
Nun benötigen wir noch eine zweite Lambda-Funktion (bei uns heißt sie „Lab-1-DynamodbToEs“, die für den entsprechenden Eintrag in einer bestehenden Eleastic-Search-Domain sorgt, sobald ein Eintrag in DynamoDB erstellt wurde. Diese setzt allerdings einen vorhandenen ElasticSearch-Cluster voraus, dessen Erstellen den Rahmen des Beitrages sprengen würde. Die Runtime ist erneut Python 2.7. Der Code hierfür ist zudem zu umfangreich für den Online-Editor in der grafischen Lambda-Console. Man kann ihn aber als ZIP-File hochladen. Als „Beschreibung“ verwenden wir „Lab 1 – DynamoDB to Elasticsearch“.

Als Trigger verwenden wir diesmal „DynamoDB“. Als Batch-Size nehmen wir „50“ Datensätze und als „Startposition“ „Neuste“. Um die Integration mit Lambda nicht ins Leere laufen zu lassen, haben wie den zugehörigen ES-Cluster zuvor aus einer AWS-Vorlage erstellt; auch der Code der zweiten Lambda-Funktion stammt aus einen Übungs-Fundus von AWS und soll hier nicht weiter thematisiert werden. Die Erweiterung demonstriert aber eindrucksvoll, wie man ergänzend zum DynamoDB-Index mit relativ einfachen Mitteln serverlos eine leistungsfähige Volltextsuche implementieren könnte. Wir behalten uns eine Erweiterung des Beispiels für einen künftigen Beitrag vor.
Testen der Funktionalität
Für einen Test der Funktionalität verwenden einen Twitter-Storm, der von einem Python-Script auf Basis von in einen S3-Bucket veröffentlichten Beispieldatensätzen generiert wird. Das Python-Script führen wir auf einer EC2-Instanz aus, um netzwerktechnisch Zugriff auf die beteiligten Ressourcen zu haben. Wir müssen unser Python-Skript dazu so konfigurieren, dass Daten in dem von uns bereitgestellten Kinesis-Firehose-Delivery-Stream veröffentlicht werden.

Dann starten wir unser Python-Script, das die Twitterstorm-Testdatensätze aus dem Testdatensatz-Bereitstellung-S3-Bucket auf unseren Delivery-Stream veröffentlicht:
python TwitterStorm.py startDer Vorgang lässt sich mit ...
tail –f /tmp/TwitterStorm.log ... verfolgen, da unserer Skript so gestaltet ist, dass es dieser Log-Datei generiert.
Fassen wir noch einmal zusammen, was passiert:
- das Skript auf der Amazon EC2 Instanz sendet permanent Daten zum Firehose Delivery Stream
- Firehose sendet die Daten seinerseits zu S3
- Amazon S3 triggert eine Lambda Funktion, die mit jedem neuen Upload eine Referenz in DynamoDB ablegt
- DynamoDB triggert eine weitere Lambda-Funktion, die die Daten simultan in Elastis Search ablegt

Es dauert einige Minuten, bis die Daten durch das gesamte System fließen. Um die durch den Data Lake fließenden Daten zu verfolgen und um sicherzustellen, dass der Data Lake wie geplant funktioniert, wechseln wir in der Management Console zu „Kinesis“ und klicken in unserem Delivery-Stream „datastream“ auf „Monitoring“, um die Stream-Aktualisierungen zu beobachten. Die Daten sind auch in S3 sowie in der DynamoDB-Konsole sichtbar.

Für das Durchsuchen unseres ElasticSearch-Clusters bzw. der Elastic-Search-Domain müssten wir indes in einem der nächsten Teile noch eine API veröffentlichen und dann eine passendende Web-Anwendung zum Abrufen der Daten schreiben. Diese soll ebenfalls statisch auf S3 gehostet werden, um weiterhin ohne EC2-Server auszukommen. Der EC2-Maschine in diesem Beispiel diente ja nur als Basis für ein Python-Script, um die Testdaten zu generieren.
(ID:45685441)
:quality(80)/p7i.vogel.de/wcms/a9/fe/a9fec7f9357565b2162ddb6389b32dc5/0116134867.jpeg "Die AWS-Verantwortlichen Jonathan Weiss (links) und Christian Schlaeger berichten über aktuelle KI-Implementierungen des Cloud-Spezialisten. (Bild: AWS)")
:quality(80)/p7i.vogel.de/wcms/3a/33/3a3346373865b667318d79148a379999/0115700332.jpeg "Git-Hub-Secrets dienen letztlich dem sicheren Speichern von Verbindungsschlüssel, außerhalb des Codes. (Bild: Drilling / GitHub)")