Machine Learning has transformed many aspects of our everyday life, can it do the same for public services?
The past few years have seen machine learning emerge as one of the trendiest topics within the technology sector as it allows computers to find hidden insights from the volumes of data being collected without being explicitly programmed where to look. The resources available to process it have increased dramatically. One of the exciting aspects about machine learning is that its applications are virtually endless and in fact it has been transforming a wide variety of industries in interesting ways..
In this post, I would like to share my experience using machine learning algorithms, in particular how we, at Capgemini, have developed the capabilities to successfully integrate machine learning-based technology into a framework to help improve service delivery in the public sector.
Machine learning in everyday life
Many machine learning applications are all around us: Amazon and Netflix online recommendation systems, Spotify and Pandora’s personalised playlists, Facebook’s automatic face recognition and friends recommendations, Google’s personalised searches and adds, Uber’s prediction of customer demand and pre-location of cars, to mention just a few. And the future potential is virtually endless, as demonstrated by a computer beating a top-ranked player at the ancient game Go, and last week’s announcement about Google’s coalition with carmakers, which is another step towards making driverless cars a reality.
Machine learning for better customer assurance
Traditionally the target of risk classification problems is identifying non-compliant customers or fraudulent behaviour. Assurance scoring changes this emphasis to find those applications that can be confidently classified as posing negligible risk. For instance, this could enable straight-forward applications to be fast tracked, so only exceptions and high risk cases are investigated manually. At the core of Assurance scoring is supervised machine learning where data from different sources and historical known fraudulent cases are used to build a predictive model that gives a score to applications which classifies them as either high and low risk.
Selecting features to identify customer risk
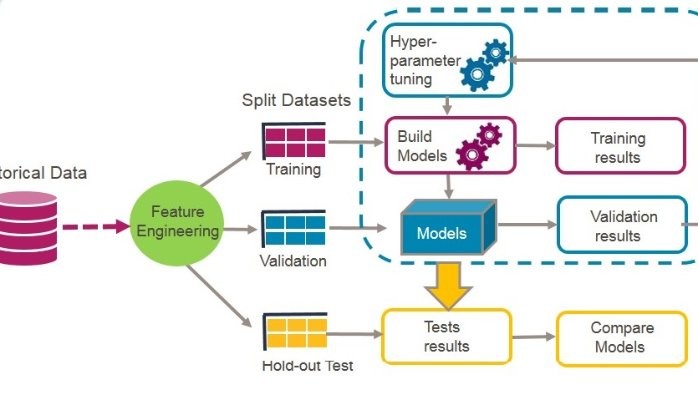
The development of the machine learning framework is a process that starts by carefully defining the requirements (next week’s blog from my colleague Toby Gamm). This is followed by an iterative process that involves building and testing multiple models over a dataset as illustrated in the figure below.

In my experience much of the initial effort goes into finding those key attributes or variables that will be useful to score future applications and classify them as either low or high risk. For example, for one of our clients, we used information from open and commercial sources as well as their own datasets to enhance applicant profile. This data enrichment requires pipelines of data pre-processing and transformations, so that the information can be explored and analysed. I believe that this part of the process provides an excellent opportunity to be creative, and for example, include novel analytical tools for feature engineering. For instance, using text mining and sentiment analysis in some of our data proved to be a very useful way to uncover new relationships with the target population.
Whilst having a large number of features may seem like a good idea, there is a balance, between the number of potential predictors and the ability of the model to generalise, that is, to score correctly future applications. In my experience, a successful approach to select the best performing attributes is to combine domain expertise and computer power in an iterative process. For example, features can be pre-selected using statistical tests to determine their significance and then ranked by a simple model according to their predictive power (a decision tree or an ensemble of trees can be a good starting point). The most performing features can be then validated or challenged by the Product Owners so that their knowledge and business insights are integrated into the selection process.
Building predictive models: try, tune, test
The next step is model building, and my advice is to try and evaluate different models and make the best use of the available historical data by for example, having three different split sets. With the first two, training and calibration, model parameters can be optimised using cross-validation procedures. The third one, a ”hold out” set (not used during model training neither during the feature selection process) can be used for final testing and model comparison. By testing on a hold out set, a better indication of the models’ ability to generalise well on future new cases (the goal of any predictive model) can be estimated. Within Assurance Scoring we use this along with other techniques to ensure model quality and we repeat this process until a good set of features and a good model are found.
Incorporating business rules
But what makes a model a “good model”? There is no simple answer for this neither a simple measure that can be used to fit all problems and it is important to work with clients to design business processes that will work well with reasonable predictions. For example, it is important to understand how the business will use the model’s results. Typically, scores are combined with a single threshold to convert it into a decision procedure (i.e.: fast track applications with scores lower than certain level, assumed to be low risk). To do this, a balance between the true-positives (applications the model correctly classifies as high risk), false-positives (applications the model scores as high risk but are not) and the false-negatives (applications the model scores as low risk but were in fact high risk) is essential. I suggest using ROC curves, including the AUC (area under the curve) as a proxy measure for tuning scoring procedures until a good trade-off is found.
In Assurance Scoring, the threshold is chosen as a business driven compromise between these and other metrics such as recall & precision as well as other practical factors; we understand that the time spent researching and discussing these metrics with clients and setting expectations right from the beginning is more valuable that endless tweaking and tuning of a machine learning algorithm. My colleague Matt’s blog discussed how the model’s score is only the first step into putting applications into the low/high risk groups and how valuable it is to include other analytical tools that incorporate business rules to optimise this classification.
Use framework accelerators to build a prototype quickly
Within Assurance Scoring we designed a framework that allows the data scientist to explore, test and assess different techniques at different stages of the machine learning process, from the data exploration and feature engineering to the model build and execution. The framework provides some structure and allows you to experiment with many ready-to-go functions and techniques to easily compare what works and what doesn't. I find that one of the greatest advantages is that the framework has been built around robust testing procedures, to guarantee the end to end performance.
Data scientists translate requirements into the analytical solution
Assurance Scoring is also about an experienced team of data scientists and data engineers that digs beneath the surface to uncover the structure of the business problem and captures it into the requirements to design an analytical solution. I invite you to check our website and the services we offer in our brochure
If you would like to know more details on how we built the Assurance Scoring framework, come to our talk in the next PyData Conference on the 8th of May.
And finally, if you’d like to be part of Capgemini’s data science team, you can apply to join! Here are the job specs for our Data Science and Big Data Engineering roles.
Development Director - Data Science and Machine Learning, Oracle
7yGood read. Thanks for writing.
Data Scientist
7yNicely elaborated from start to end of model building functionalities. Thanks!
Digital Strategy Consultant @ Tata Consultancy Services
7yGood one..
Senior Deep Learning Data Scientist at NVIDIA
7yIt is great to see someone appreciate the art of feature engineering. It is surprising how many people think that you can just pass the data without any pre-work. From your experience, how iterative is the process of choosing the right thresholds? To what extent was the business involved in the process?